Más sobre forecasting en: cienciadedatos.net
- Forecasting series temporales con machine learning
- Modelos ARIMA y SARIMAX
- Forecasting series temporales con gradient boosting: XGBoost, LightGBM y CatBoost
- Global Forecasting: Multi-series forecasting
- Forecasting de la demanda eléctrica con machine learning
- Forecasting con deep learning
- Forecasting de visitas a página web con machine learning
- Forecasting del precio de Bitcoin
- Forecasting probabilístico
- Forecasting de demanda intermitente
- Reducir el impacto del Covid en modelos de forecasting
- Modelar series temporales con tendencia utilizando modelos de árboles

Introducción¶
Una serie temporal (time series) es una sucesión de datos ordenados cronológicamente, espaciados a intervalos iguales o desiguales. El proceso de forecasting consiste en predecir el valor futuro de una serie temporal, bien modelando la serie únicamente en función de su comportamiento pasado (autorregresivo) o empleando otras variables externas.
En este documento se muestra un ejemplo de cómo utilizar métodos machine learning para predecir el número de visitas diarias que recibe una página web. Para ello, se hace uso de skforecast, una librería de Python que permite, entre otras cosas, adaptar cualquier regresor de scikit-learn a problemas de forecasting.
✏️ Note
Otros dos ejemplos de cómo utilizar modelos de machine learning para forecasting:
Caso de uso¶
Se dispone del historial de visitas diarias a la web cienciadedatos.net desde el 01/07/2020. Se pretende generar un modelo de forecasting capaz de predecir el tráfico web que tendrá la página a 7 días vista. En concreto, el usuario quiere ser capaz de ejecutar el modelo cada lunes y obtener las predicciones de tráfico diario hasta el lunes siguiente.
Con el objetivo de poder evaluar de forma robusta la capacidad del modelo acorde al uso que se le quiere dar, conviene no limitarse a predecir únicamente los últimos 7 días de la serie temporal, sino simular el proceso completo. El backtesting es un tipo especial de cross-validation que se aplica al periodo o periodos anteriores y puede emplearse con diferentes estrategias:
Backtesting con reentrenamiento
El modelo se entrena cada vez antes de realizar las predicciones, de esta forma, se incorpora toda la información disponible hasta el momento. Se trata de una adaptación del proceso de cross-validation en el que, en lugar de hacer un reparto aleatorio de las observaciones, el conjunto de entrenamiento se incrementa de manera secuencial, manteniendo el orden temporal de los datos.
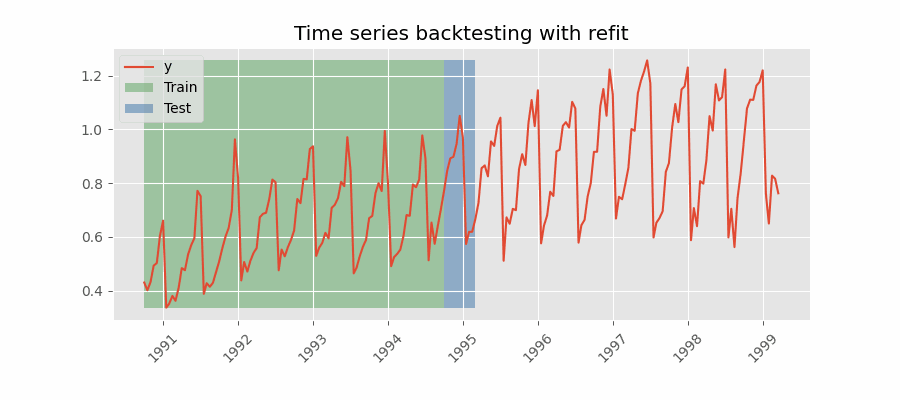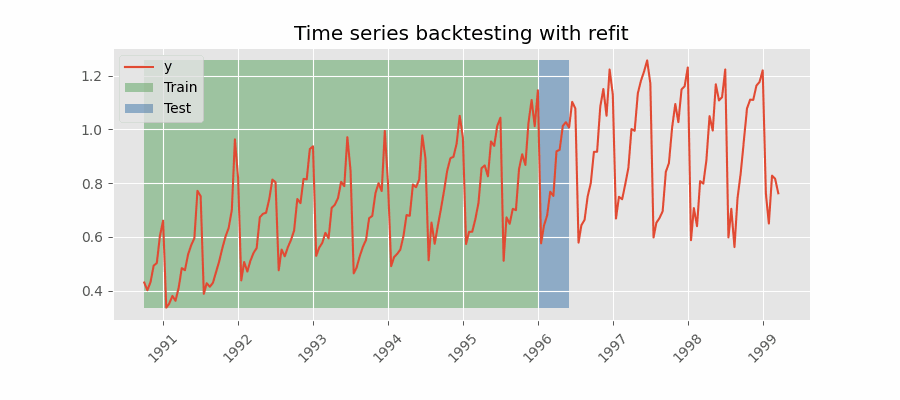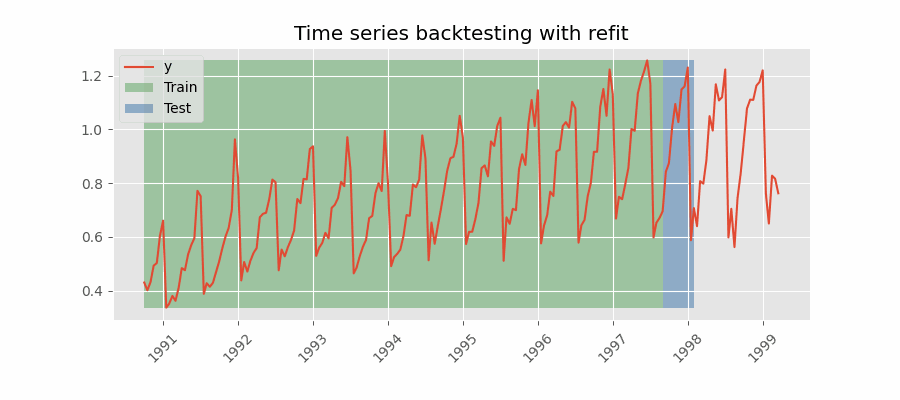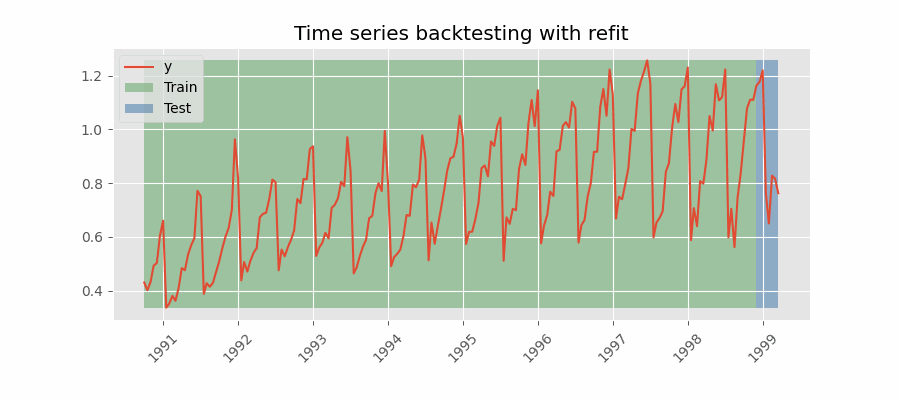
Backtesting con reentrenamiento y tamaño de entrenamiento constante
Similar a la estrategia anterior, pero, en este caso, el tamaño del conjunto de entrenamiento no se incrementa sino que la ventana de tiempo que abarca se desplaza. Esta estrategia se conoce también como time series cross-validation o walk-forward validation.
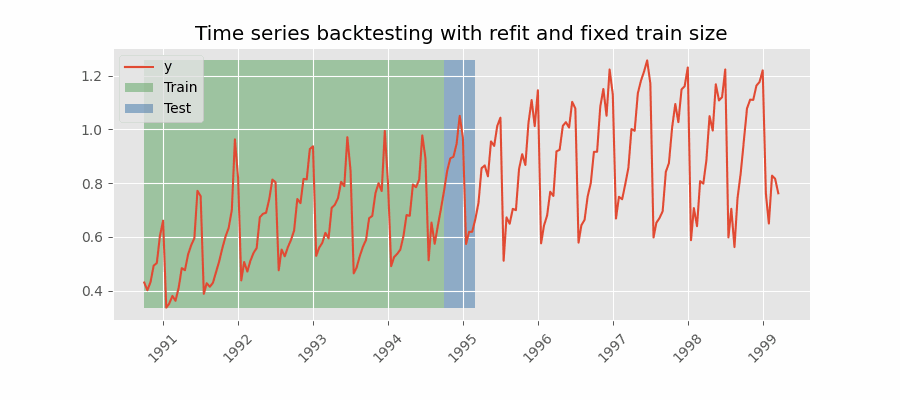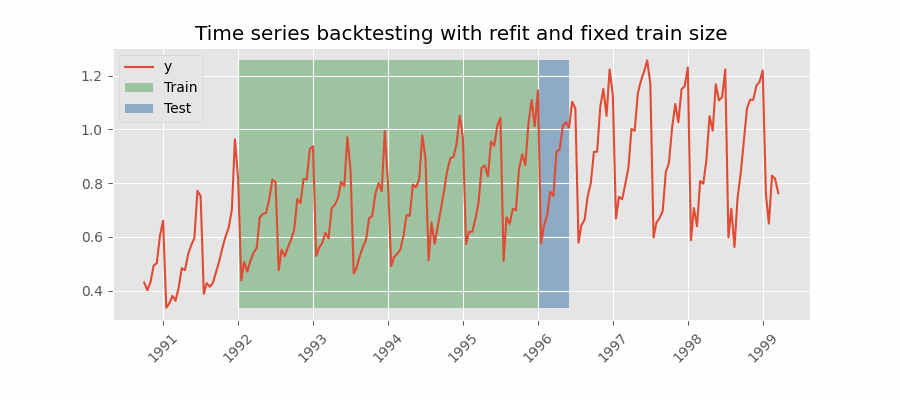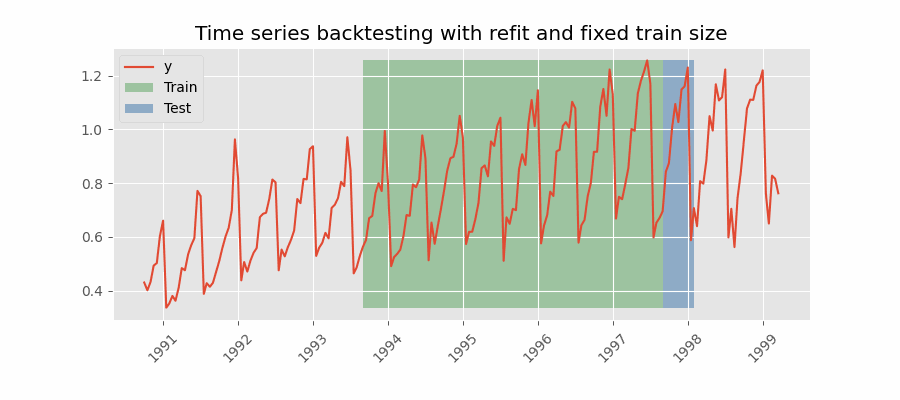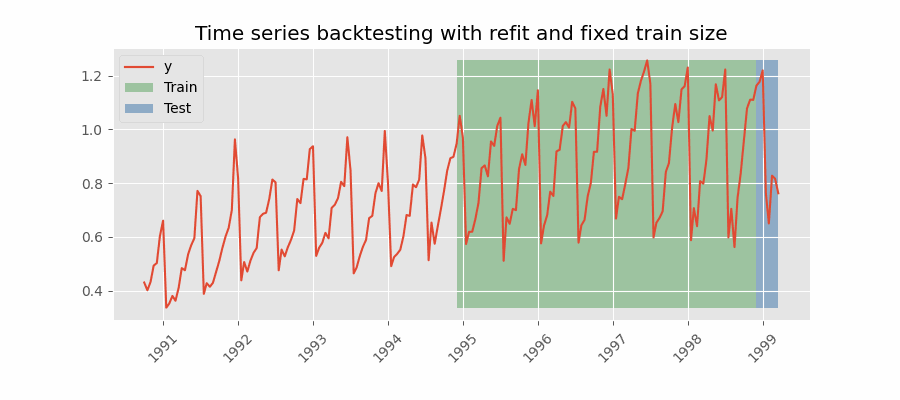
Backtesting con reentrenamiento cada n periodos (intermitente)
El modelo se reentrena de forma intermitente cada $n$ periodos de predicción.
💡 Tip
Esta estrategia suele lograr un buen equilibrio entre el coste computacional del reentrenamiento y evitar la degradación del modelo.
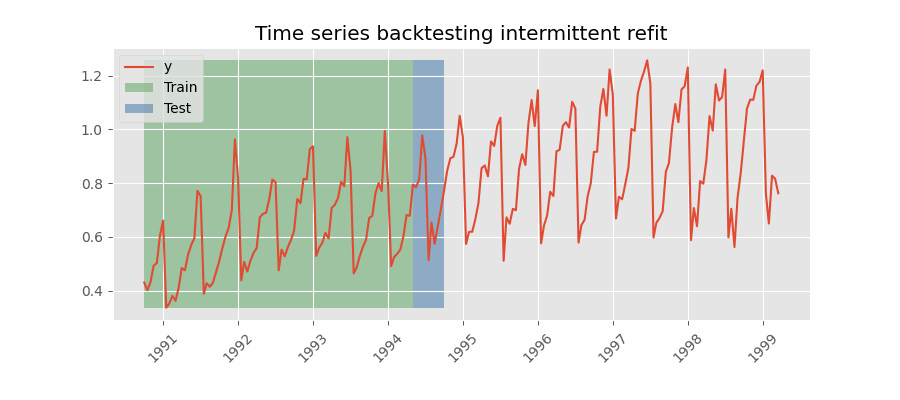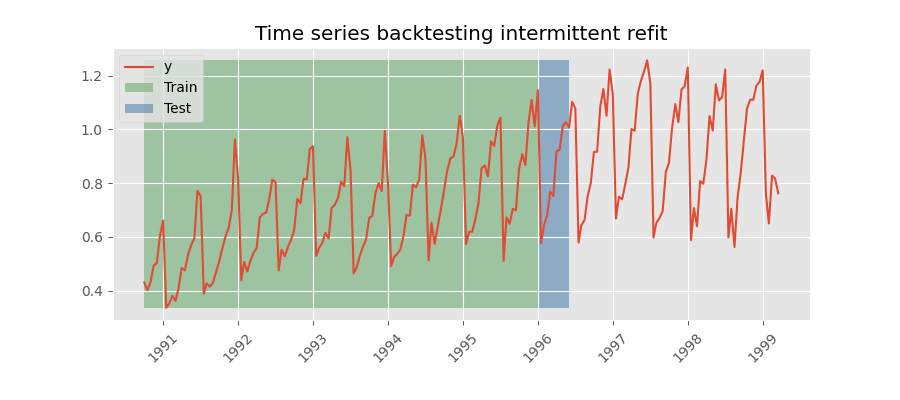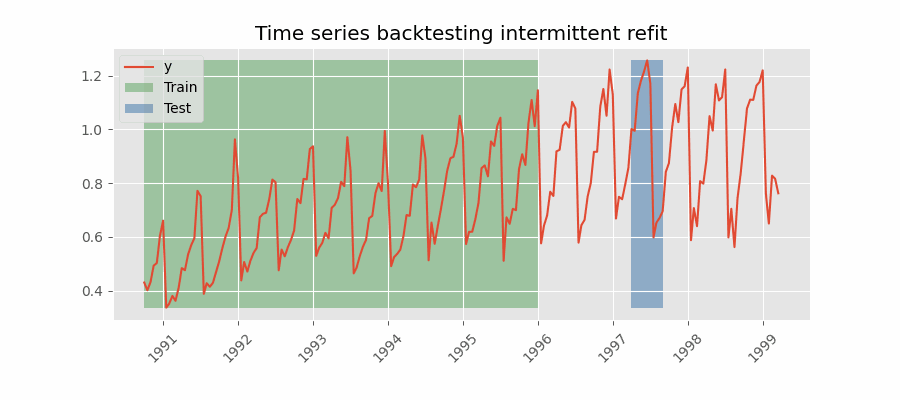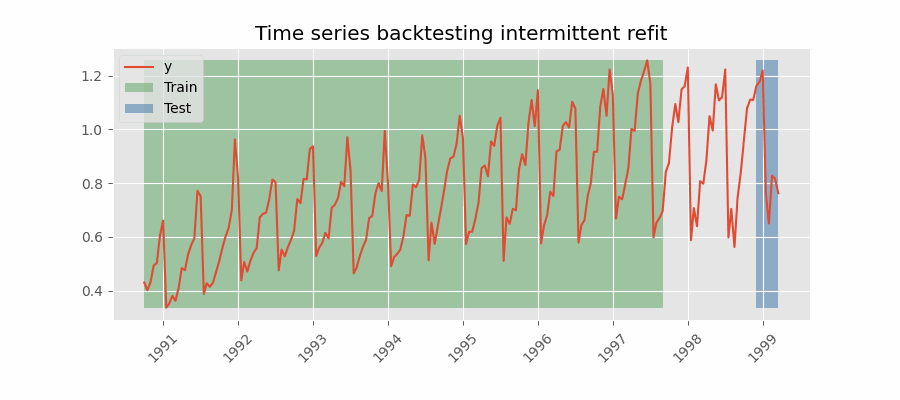
Backtesting sin reentrenamiento
Con esta estrategia, el modelo se entrena una única vez con un conjunto inicial y se realizan las predicciones de forma secuencial sin actualizar el modelo y siguiendo el orden temporal de los datos. Esta estrategia tiene la ventaja de ser mucho más rápida puesto que el modelo solo se entrena una vez. La desventaja es que el modelo no incorpora la última información disponible por lo que puede perder capacidad predictiva con el tiempo.
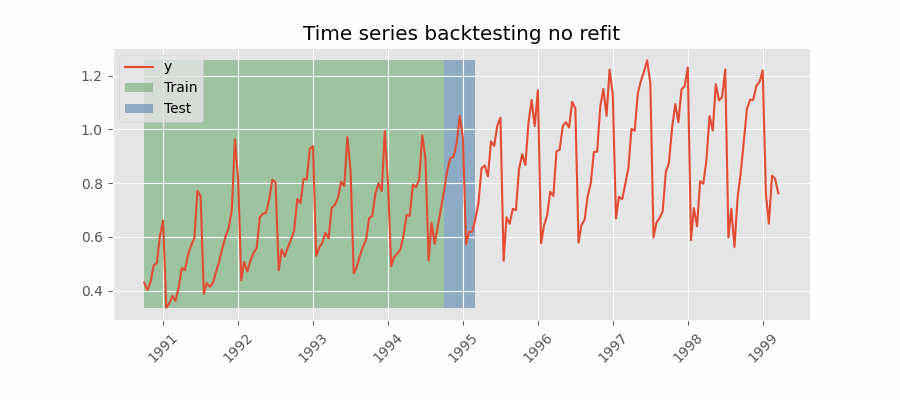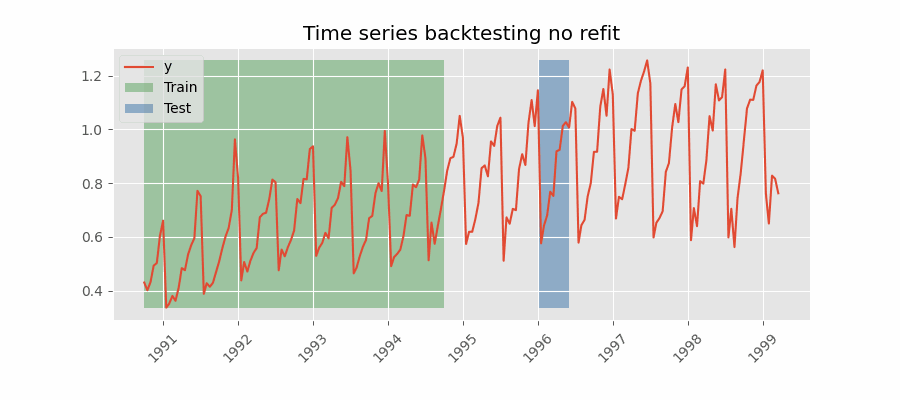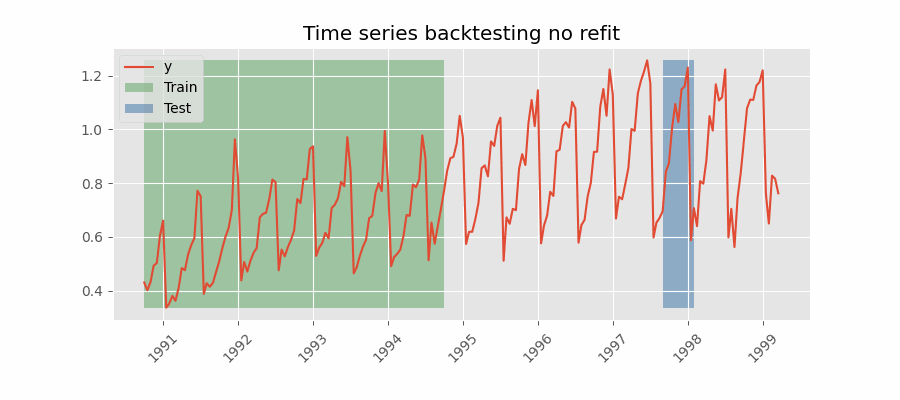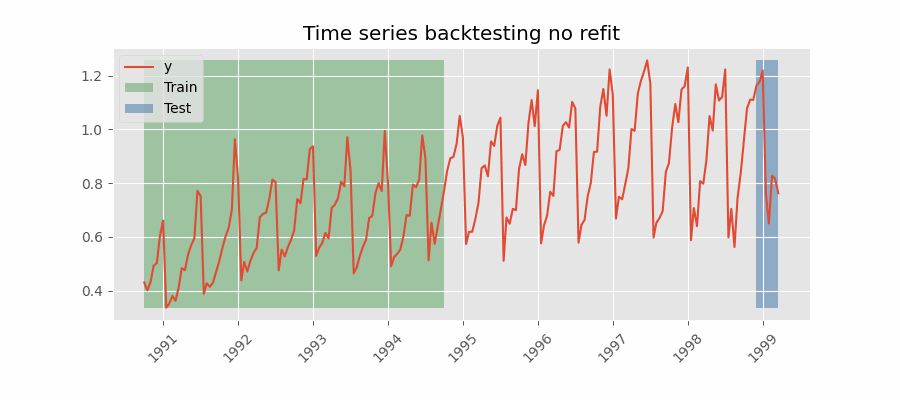
El método de validación más adecuada dependerá de cuál sea la estrategia seguida en la puesta en producción, en concreto, de si el modelo se va a reentrenar periódicamente o no antes de que se ejecute el proceso de predicción. Independientemente de la estrategia utilizada, es importante no incluir los datos de test en el proceso de búsqueda para no caer en problemas de overfitting.
Para este ejemplo, se sigue una estrategia de backtesting con reentrenamiento. Internamente, el proceso seguido por la función es el siguiente:
En la primera iteración, el modelo se entrena con las observaciones seleccionadas para el entrenamiento inicial. Después, se predicen las siguien 7 observaciones (7 días).
En la segunda iteración, se reentrena el modelo extendiendo el conjunto de entrenamiento inicial en 7 observaciones, y se predicen las 7 siguientes.
Este proceso se repite hasta que se utilizan todas las observaciones disponibles y se calcula la métrica de validación con todas las predicciones acumuladas. Siguiendo esta estrategia, el conjunto de entrenamiento aumenta en cada iteración con tantas observaciones como steps se estén prediciendo.
Librerías¶
Las librerías utilizadas en este documento son:
# Tratamiento de datos
# ==============================================================================
import numpy as np
import pandas as pd
from skforecast.datasets import fetch_dataset
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import plotly.graph_objects as go
import plotly.io as pio
import plotly.offline as poff
pio.templates.default = "seaborn"
poff.init_notebook_mode(connected=True)
plt.style.use('seaborn-v0_8-darkgrid')
# Modelado y Forecasting
# ==============================================================================
import skforecast
import sklearn
from sklearn.linear_model import Ridge
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import make_column_transformer
from skforecast.recursive import ForecasterRecursive, ForecasterEquivalentDate
from skforecast.model_selection import TimeSeriesFold, grid_search_forecaster, backtesting_forecaster
from skforecast.stats import calculate_lag_autocorrelation
import shap
# Configuración warnings
# ==============================================================================
import warnings
warnings.filterwarnings('once')
color = '\033[1m\033[38;5;208m'
print(f"{color}Versión skforecast: {skforecast.__version__}")
print(f"{color}Versión scikit-learn: {sklearn.__version__}")
print(f"{color}Versión pandas: {pd.__version__}")
print(f"{color}Versión numpy: {np.__version__}")
Versión skforecast: 0.23.0 Versión scikit-learn: 1.7.2 Versión pandas: 2.3.3 Versión numpy: 2.4.6
Datos¶
# Descarga de datos
# ==============================================================================
datos = fetch_dataset(name="website_visits", raw=True)
╭───────────────────────────── website_visits ──────────────────────────────╮ │ Description: │ │ Daily visits to the cienciadedatos.net website registered with the google │ │ analytics service. │ │ │ │ Source: │ │ Amat Rodrigo, J. (2021). cienciadedatos.net (1.0.0). Zenodo. │ │ https://doi.org/10.5281/zenodo.10006330 │ │ │ │ URL: │ │ https://raw.githubusercontent.com/skforecast/skforecast- │ │ datasets/main/data/visitas_por_dia_web_cienciadedatos.csv │ │ │ │ Shape: 421 rows x 2 columns │ ╰───────────────────────────────────────────────────────────────────────────╯
La columna date se ha almacenado como string. Para convertirla en formato fecha, se emplea la función pd.to_datetime(). Una vez en formato datetime, y para hacer uso de las funcionalidades de pandas, se establece como índice. Además, dado que los datos son de carácter diario, se indica la frecuencia ('1D').
# Conversión del formato fecha
# ==============================================================================
datos['date'] = pd.to_datetime(datos['date'], format='%d/%m/%y')
datos = datos.set_index('date')
datos = datos.asfreq('1D')
datos = datos.sort_index()
datos.head(3)
| users | |
|---|---|
| date | |
| 2020-07-01 | 2324 |
| 2020-07-02 | 2201 |
| 2020-07-03 | 2146 |
# Verificar que un índice temporal está completo y no hay valores faltantes
# ==============================================================================
fecha_inicio = datos.index.min()
fecha_fin = datos.index.max()
date_range_completo = pd.date_range(start=fecha_inicio, end=fecha_fin, freq=datos.index.freq)
print(f"Índice completo: {(datos.index == date_range_completo).all()}")
print(f"Filas con valores ausentes: {datos.isnull().any(axis=1).mean()}")
Índice completo: True Filas con valores ausentes: 0.0
El set de datos empieza el 2020-07-01 y termina el 2021-08-22. Se dividen los datos en 3 conjuntos, uno de entrenamiento, uno de validación y otro de test.
# Separación datos train-test
# ==============================================================================
fin_train = '2021-03-30 23:59:00'
fin_validacion = '2021-06-30 23:59:00'
datos_train = datos.loc[: fin_train, :]
datos_val = datos.loc[fin_train:fin_validacion, :]
datos_test = datos.loc[fin_validacion:, :]
print(f"Fechas train : {datos_train.index.min()} --- {datos_train.index.max()} (n={len(datos_train)})")
print(f"Fechas validación : {datos_val.index.min()} --- {datos_val.index.max()} (n={len(datos_val)})")
print(f"Fechas test : {datos_test.index.min()} --- {datos_test.index.max()} (n={len(datos_test)})")
Fechas train : 2020-07-01 00:00:00 --- 2021-03-30 00:00:00 (n=273) Fechas validación : 2021-03-31 00:00:00 --- 2021-06-30 00:00:00 (n=92) Fechas test : 2021-07-01 00:00:00 --- 2021-08-25 00:00:00 (n=56)
Exploración gráfica¶
Cuando se quiere generar un modelo de forecasting, es importante representar los valores de la serie temporal. Esto permite identificar patrones tales como tendencias y estacionalidad.
Serie temporal completa
# Gráfico serie temporal
# ==============================================================================
fig = go.Figure()
fig.add_trace(go.Scatter(x=datos_train.index, y=datos_train['users'], mode='lines', name='Train'))
fig.add_trace(go.Scatter(x=datos_val.index, y=datos_val['users'], mode='lines', name='Validation'))
fig.add_trace(go.Scatter(x=datos_test.index, y=datos_test['users'], mode='lines', name='Test'))
fig.update_layout(
title = 'Visitas diarias',
xaxis_title="Fecha",
yaxis_title="Users",
width=750,
height=350,
margin=dict(l=20, r=20, t=35, b=20),
legend=dict(orientation="h", yanchor="top", y=1.12, xanchor="left", x=0.001)
)
fig.show()
Estacionalidad
fig, axs = plt.subplot_mosaic(
"""
AB
CC
""",
sharey=True
)
# Users distribution by month
datos['month'] = datos.index.month
datos.boxplot(column='users', by='month', ax=axs['A'])
datos.groupby('month')['users'].median().plot(style='o-', linewidth=0.8, ax=axs['A'])
axs['A'].set_ylabel('Users')
axs['A'].set_title('Distribución de visitas por mes', fontsize=9)
# Users distribution by week day
datos['week_day'] = datos.index.day_of_week + 1
datos.boxplot(column='users', by='week_day', ax=axs['B'])
datos.groupby('week_day')['users'].median().plot(style='o-', linewidth=0.8, ax=axs['B'])
axs['B'].set_ylabel('Users')
axs['B'].set_title('Distribución de visitas por día de la semana', fontsize=9)
# Users distribution by month day
datos['month_day'] = datos.index.day
datos.boxplot(column='users', by='month_day', ax=axs['C'])
datos.groupby('month_day')['users'].median().plot(style='o-', linewidth=0.8, ax=axs['C'])
axs['C'].set_ylabel('Users')
axs['C'].set_title('Distribución de visitas por día del mes', fontsize=9)
fig.suptitle("Gráfico de estacionalidad", fontsize=12)
fig.tight_layout()

Al no disponer de dos años de histórico completos, no se puede determinar si existe una estacionalidad anual. Sí se aprecia una estacionalidad semanal, con una reducción del tráfico web los fines de semana.
Gráficos de autocorrelación
Los gráficos de autocorrelación muestran la correlación entre una serie temporal y sus valores pasados. Son una herramienta útil para identificar el orden de un modelo autorregresivo, es decir, los valores pasados (lags) que se deben incluir en el modelo.
La función de autocorrelación (ACF) mide la correlación entre una serie temporal y sus valores pasados. La función de autocorrelación parcial (PACF) mide la correlación entre una serie temporal y sus valores pasados, pero solo después de eliminar las variaciones explicadas por los valores pasados intermedios.
# Gráfico autocorrelación
# ==============================================================================
fig, ax = plt.subplots(figsize=(5, 2))
plot_acf(datos['users'], ax=ax, lags=50, fft=True)
plt.show()

# Gráfico autocorrelación parcial
# ==============================================================================
fig, ax = plt.subplots(figsize=(5, 2))
plot_pacf(datos['users'], ax=ax, lags=50, method='burg')
plt.show()

# Top 10 lags con mayor autocorrelación parcial
# ==============================================================================
calculate_lag_autocorrelation(
data = datos['users'],
n_lags = 60,
sort_by = "partial_autocorrelation_abs"
).head(10)
| lag | partial_autocorrelation_abs | partial_autocorrelation | autocorrelation_abs | autocorrelation | |
|---|---|---|---|---|---|
| 0 | 1 | 0.865897 | 0.865897 | 0.865897 | 0.865897 |
| 1 | 8 | 0.660998 | -0.660998 | 0.739243 | 0.739243 |
| 2 | 6 | 0.558165 | 0.558165 | 0.782706 | 0.782706 |
| 3 | 5 | 0.376389 | 0.376389 | 0.636391 | 0.636391 |
| 4 | 3 | 0.325238 | 0.325238 | 0.598038 | 0.598038 |
| 5 | 15 | 0.275001 | -0.275001 | 0.577816 | 0.577816 |
| 6 | 2 | 0.259590 | -0.259590 | 0.684822 | 0.684822 |
| 7 | 22 | 0.168378 | -0.168378 | 0.392733 | 0.392733 |
| 8 | 23 | 0.154417 | 0.154417 | 0.221251 | 0.221251 |
| 9 | 7 | 0.152392 | 0.152392 | 0.874265 | 0.874265 |
Los gráficos de autocorrelación y autocorrelación parcial muestran una clara asociación entre el número de usuarios un día y los días anteriores. Este tipo de correlación, es un indicativo de que los modelos autorregresivos pueden funcionar bien.
Baseline¶
Al enfrentarse a un problema de forecasting, es recomendable disponer de un modelo de referencia (baseline). Se trata de un modelo muy sencillo que puede utilizarse como referencia para evaluar si merece la pena aplicar modelos más complejos.
Skforecast permite crear fácilmente un modelo de referencia con su clase ForecasterEquivalentDate. Este modelo, también conocido como Seasonal Naive Forecasting, simplemente devuelve el valor observado en el mismo periodo de la temporada anterior (por ejemplo, el mismo día laboral de la semana anterior, la misma hora del día anterior, etc.).
A partir del análisis exploratorio realizado, el modelo de referencia será el que prediga cada hora utilizando el valor de la misma hora del día anterior.
# Crear baseline: valor del día previo
# ==============================================================================
forecaster = ForecasterEquivalentDate(
offset = pd.DateOffset(days=1),
n_offsets = 1
)
# Entrenar forecaster
# ==============================================================================
forecaster.fit(y=datos.loc[:fin_validacion, 'users'])
forecaster
ForecasterEquivalentDate
General Information
- Estimator: NoneType
- Offset:
- Number of offsets: 1
- Aggregation function: mean
- Window size: 1
- Creation date: 2026-07-13 22:18:47
- Last fit date: 2026-07-13 22:18:47
- Skforecast version: 0.23.0
- Python version: 3.13.14
- Forecaster id: None
Training Information
- Training range: [Timestamp('2020-07-01 00:00:00'), Timestamp('2021-06-30 00:00:00')]
- Training index type: DatetimeIndex
- Training index frequency: D
# Backtesting
# ==============================================================================
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(datos.loc[:fin_validacion]),
refit = False,
)
metrica_baseline, predicciones = backtesting_forecaster(
forecaster = forecaster,
y = datos['users'],
cv = cv,
metric = 'mean_absolute_error'
)
metrica_baseline
| mean_absolute_error | |
|---|---|
| 0 | 513.035714 |
Modelo autoregresivo recursivo¶
Se crea y entrena un modelo autorregresivo recursivo (ForecasterRecursive) a partir de un modelo de regresión lineal con penalización Ridge y una ventana temporal de 2 semanas (14 lags). Esto último significa que, para cada predicción, se utilizan como predictores el tráfico que tuvo la página los 14 días anteriores.
Los modelos Ridge requieren que los predictores se estandaricen. Con este fin, se utiliza el argumento transformer_y para incorporar un StandarScaler en el forecaster. Para conocer más sobre el uso de transformers consultar Forecasting with scikit-learn and transformers pipelines.
Forecaster¶
# Crear forecaster
# ==============================================================================
forecaster = ForecasterRecursive(
estimator = Ridge(random_state=123),
lags = 14,
transformer_y = StandardScaler(),
forecaster_id = 'visitas_web'
)
Optimización de hiperparámetros (tuning)¶
Con el objetivo de identificar la mejor combinación de lags e hiperparámetros, se recurre a un Grid Search. Este proceso consiste en entrenar un modelo con cada combinación de hiperparámetros y lags, y evaluar su capacidad predictiva mediante backtesting.
En el proceso de búsqueda es importante evaluar los modelos utilizando únicamente los datos de validación y no incluir los de test, estos se utilizan solo en último lugar para evaluar al modelo final.
# Grid search de hiperparámetros
# ==============================================================================
# Hiperparámetros del regresor
param_grid = {'alpha': np.logspace(-3, 3, 10)}
# Lags utilizados como predictores
lags_grid = [7, 14, 21, [7, 14, 21]]
# Folds
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(datos_train),
refit = False,
)
resultados_grid = grid_search_forecaster(
forecaster = forecaster,
y = datos.loc[:fin_validacion, 'users'],
param_grid = param_grid,
lags_grid = lags_grid,
cv = cv,
metric = 'mean_absolute_error',
)
best_params = resultados_grid['params'].iat[0]
resultados_grid.head()
| lags | lags_label | params | mean_absolute_error | alpha | |
|---|---|---|---|---|---|
| 0 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 2.154434690031882} | 214.791677 | 2.154435 |
| 1 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.46415888336127775} | 216.551409 | 0.464159 |
| 2 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.1} | 217.770757 | 0.100000 |
| 3 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.021544346900318832} | 218.127429 | 0.021544 |
| 4 | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] | {'alpha': 0.004641588833612777} | 218.206475 | 0.004642 |
Los mejores resultados se obtienen si se utilizan los lags [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14] y una configuración de Ridge {'alpha': 2.154}. Al indicar return_best = True en la función grid_search_forecaster(), al final del proceso, se reentrena automáticamente el objeto forecaster con la mejor configuración encontrada y el set de datos completo.
forecaster
ForecasterRecursive
General Information
- Estimator: Ridge
- Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
- Window features: None
- Calendar features: None
- Window size: 14
- Series name: users
- Exogenous included: False
- Categorical features: auto
- Weight function included: False
- Differentiation order: None
- Drop NaN from series: False
- Creation date: 2026-07-13 22:18:48
- Last fit date: 2026-07-13 22:18:49
- Skforecast version: 0.23.0
- Python version: 3.13.14
- Forecaster id: visitas_web
Exogenous Variables
None
Data Transformations
- Transformer for y: StandardScaler()
- Transformer for exog: None
Training Information
- Training range: [Timestamp('2020-07-01 00:00:00'), Timestamp('2021-06-30 00:00:00')]
- Training index type: DatetimeIndex
- Training index frequency: D
Estimator Parameters
-
{'alpha': np.float64(2.154434690031882), 'copy_X': True, 'fit_intercept': True, 'max_iter': None, 'positive': False, 'random_state': 123, 'solver': 'auto', 'tol': 0.0001}
Fit Kwargs
-
{}
Predicción (backtest)¶
Se evalúa el comportamiento que habría tenido el modelo si se hubiese entrenado con los datos desde 2020-07-01 al 2021-06-30 y, después, se realizasen predicciones de 7 en 7 días sin reentrenar el modelo. A este tipo de evaluación se le conoce como backtesting, y puede aplicarse fácilmente con la función grid_search_forecaster(). Esta función devuelve, además de las predicciones, una métrica de error.
# Backtest modelo final (conjunto de test)
# ==============================================================================
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(datos.loc[:fin_validacion]),
refit = True,
fixed_train_size = False,
)
metrica, predicciones = backtesting_forecaster(
forecaster = forecaster,
y = datos.users,
cv = cv,
metric = 'mean_absolute_error',
verbose = True,
)
metrica
Information of folds
--------------------
Number of observations used for initial training: 365
Number of observations used for backtesting: 56
Number of folds: 8
Number skipped folds: 0
Number of steps per fold: 7
Number of steps to exclude between last observed data (last window) and predictions (gap): 0
Fold: 0
Training: 2020-07-01 00:00:00 -- 2021-06-30 00:00:00 (n=365)
Validation: 2021-07-01 00:00:00 -- 2021-07-07 00:00:00 (n=7)
Fold: 1
Training: 2020-07-01 00:00:00 -- 2021-07-07 00:00:00 (n=372)
Validation: 2021-07-08 00:00:00 -- 2021-07-14 00:00:00 (n=7)
Fold: 2
Training: 2020-07-01 00:00:00 -- 2021-07-14 00:00:00 (n=379)
Validation: 2021-07-15 00:00:00 -- 2021-07-21 00:00:00 (n=7)
Fold: 3
Training: 2020-07-01 00:00:00 -- 2021-07-21 00:00:00 (n=386)
Validation: 2021-07-22 00:00:00 -- 2021-07-28 00:00:00 (n=7)
Fold: 4
Training: 2020-07-01 00:00:00 -- 2021-07-28 00:00:00 (n=393)
Validation: 2021-07-29 00:00:00 -- 2021-08-04 00:00:00 (n=7)
Fold: 5
Training: 2020-07-01 00:00:00 -- 2021-08-04 00:00:00 (n=400)
Validation: 2021-08-05 00:00:00 -- 2021-08-11 00:00:00 (n=7)
Fold: 6
Training: 2020-07-01 00:00:00 -- 2021-08-11 00:00:00 (n=407)
Validation: 2021-08-12 00:00:00 -- 2021-08-18 00:00:00 (n=7)
Fold: 7
Training: 2020-07-01 00:00:00 -- 2021-08-18 00:00:00 (n=414)
Validation: 2021-08-19 00:00:00 -- 2021-08-25 00:00:00 (n=7)
| mean_absolute_error | |
|---|---|
| 0 | 211.974974 |
Variables exógenas¶
En el ejemplo anterior, se han utilizado como predictores únicamente lags de la propia variable objetivo. En ciertos escenarios, es posible disponer de información sobre otras variables, cuyo valor a futuro se conoce, y que pueden servir como predictores adicionales en el modelo. Algunos ejemplos típicos son:
Festivos (local, nacional...)
Mes del año
Día de la semana
Hora del día
En este caso de uso, el análisis gráfico mostraba evidencias de que, los fines de semana, el número de visitas a la web se reduce. El día de la semana al que corresponde cada fecha puede saberse a futuro, por lo que se puede emplear como variable exógena. Véase cómo afecta a los modelos si se incluye como predictor está información.
# Creación de nuevas variables exógenas
# ==============================================================================
datos['month'] = datos.index.month
datos['month_day'] = datos.index.day
datos['week_day'] = datos.index.day_of_week
datos.head()
| users | month | week_day | month_day | |
|---|---|---|---|---|
| date | ||||
| 2020-07-01 | 2324 | 7 | 2 | 1 |
| 2020-07-02 | 2201 | 7 | 3 | 2 |
| 2020-07-03 | 2146 | 7 | 4 | 3 |
| 2020-07-04 | 1666 | 7 | 5 | 4 |
| 2020-07-05 | 1433 | 7 | 6 | 5 |
# One hot encoding transformer
# ==============================================================================
one_hot_encoder = make_column_transformer(
(
OneHotEncoder(sparse_output=False, drop='if_binary'),
['month', 'week_day', 'month_day'],
),
remainder="passthrough",
verbose_feature_names_out=False,
).set_output(transform="pandas")
datos = one_hot_encoder.fit_transform(datos)
datos.head()
| month_1 | month_2 | month_3 | month_4 | month_5 | month_6 | month_7 | month_8 | month_9 | month_10 | ... | month_day_23 | month_day_24 | month_day_25 | month_day_26 | month_day_27 | month_day_28 | month_day_29 | month_day_30 | month_day_31 | users | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2020-07-01 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2324 |
| 2020-07-02 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2201 |
| 2020-07-03 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2146 |
| 2020-07-04 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1666 |
| 2020-07-05 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1433 |
5 rows × 51 columns
# Separación datos train-test
# ==============================================================================
datos_train = datos.loc[: fin_train, :]
datos_val = datos.loc[fin_train:fin_validacion, :]
datos_test = datos.loc[fin_validacion:, :]
exog_features = [col for col in datos.columns if col.startswith(('month_', 'week_day_', 'month_day_'))]
# Crear y entrenar forecaster
# ==============================================================================
forecaster = ForecasterRecursive(
estimator = Ridge(**best_params, random_state=123),
lags = 14,
transformer_y = StandardScaler(),
forecaster_id = 'visitas_web'
)
# Backtest modelo con variables exógenas
# ==============================================================================
metrica, predicciones = backtesting_forecaster(
forecaster = forecaster,
y = datos.users,
exog = datos[exog_features],
cv = cv,
metric = 'mean_absolute_error',
)
display(metrica)
predicciones.head(5)
| mean_absolute_error | |
|---|---|
| 0 | 149.058991 |
| fold | pred | |
|---|---|---|
| 2021-07-01 | 0 | 3109.259189 |
| 2021-07-02 | 0 | 2914.336919 |
| 2021-07-03 | 0 | 2318.810952 |
| 2021-07-04 | 0 | 1957.766737 |
| 2021-07-05 | 0 | 3002.216742 |
# Gráfico predicciones vs valor real
# ======================================================================================
fig = go.Figure()
trace1 = go.Scatter(x=datos_test.index, y=datos_test['users'], name="test", mode="lines")
trace2 = go.Scatter(x=predicciones.index, y=predicciones['pred'], name="prediction", mode="lines")
fig.add_trace(trace1)
fig.add_trace(trace2)
fig.update_layout(
title="Valor real vs predicciones en test",
xaxis_title="Fecha",
yaxis_title="Users",
width=750,
height=350,
margin=dict(l=20, r=20, t=35, b=20),
legend=dict(orientation="h", yanchor="top", y=1.11, xanchor="left", x=0.001)
)
fig.show()
Por último, el modelo se entrena utilizando los mejores parámetros, lags y todos los datos disponibles.
# Crear y entrenar el forecaster con los mejores hiperparámetros y lags
# ==============================================================================
forecaster = ForecasterRecursive(
estimator = Ridge(**best_params, random_state=123),
lags = 14,
transformer_y = StandardScaler(),
forecaster_id = 'web_traffic'
)
forecaster.fit(y=datos['users'], exog=datos[exog_features], store_in_sample_residuals=True)
Importancia de predictores¶
Skforecast es compatible con algunos de los métodos de explicabilidad más populares: model-specific feature importances, SHAP values, and partial dependence plots.
Importancia model-specific
# Extraer importancia de los predictores
# ==============================================================================
importancia = forecaster.get_feature_importances()
importancia.head(10)
| feature | importance | |
|---|---|---|
| 0 | lag_1 | 0.753168 |
| 26 | week_day_0 | 0.411202 |
| 5 | lag_6 | 0.230151 |
| 24 | month_11 | 0.195164 |
| 6 | lag_7 | 0.166955 |
| 30 | week_day_4 | 0.096308 |
| 2 | lag_3 | 0.092973 |
| 55 | month_day_23 | 0.091812 |
| 35 | month_day_3 | 0.090239 |
| 23 | month_10 | 0.086671 |
⚠️ Warning
get_feature_importances() solo devuelve valores si el regresor utilizado dentro del forecaster tiene el atributo coef_ o feature_importances_.
Shap values
Los valores SHAP (SHapley Additive exPlanations) son un método muy utilizado para explicar los modelos de machine learning, ya que ayudan a comprender cómo influyen las variables y los valores en las predicciones de forma visual y cuantitativa.
Se puede obtener un análisis SHAP a partir de modelos skforecast con sólo dos elementos:
El regresor interno del forecaster.
Las matrices de entrenamiento creadas a partir de la serie temporal y variables exógenas, utilizadas para ajustar el pronosticador.
Aprovechando estos dos componentes, los usuarios pueden crear explicaciones interpretables para sus modelos de skforecast. Estas explicaciones pueden utilizarse para verificar la fiabilidad del modelo, identificar los factores más significativos que contribuyen a las predicciones y comprender mejor la relación subyacente entre las variables de entrada y la variable objetivo.
# Matrices de entrenamiento utilizadas por el forecaster para entrenar el regresor
# ==============================================================================
X_train, y_train = forecaster.create_train_X_y(
y = datos_train['users'],
exog = datos_train[exog_features]
)
# Crear SHAP explainer (para modelos lineales)
# ==============================================================================
explainer = shap.LinearExplainer(forecaster.estimator, X_train)
shap_values = explainer.shap_values(X_train)
# Shap summary plot (top 10)
# ==============================================================================
shap.initjs()
shap.summary_plot(shap_values, X_train, max_display=10, show=False)
fig, ax = plt.gcf(), plt.gca()
ax.set_title("SHAP Summary plot")
ax.tick_params(labelsize=8)
fig.set_size_inches(6, 3.5)


Forecasting probabilistico: Intervalos de predicción¶
Un intervalo de predicción define el intervalo dentro del cual se puede esperar que se encuentre el valor verdadero de la variable objetivo con una probabilidad dada. Skforecast implementa varios métodos para el forecasting probabilístico:
La función backtesting_forecaster permite obtener, además de las predicciones, sus intervalos.
# Backtest modelo con variables exógenas
# ==============================================================================
metrica, predicciones = backtesting_forecaster(
forecaster = forecaster,
y = datos.users,
exog = datos[exog_features],
cv = cv,
metric = 'mean_absolute_error',
interval = [0.1, 0.9],
n_boot = 250
)
display(metrica)
predicciones.head(5)
| mean_absolute_error | |
|---|---|
| 0 | 149.058991 |
| fold | pred | lower_bound | upper_bound | |
|---|---|---|---|---|
| 2021-07-01 | 0 | 3109.259189 | 3004.224962 | 3310.050325 |
| 2021-07-02 | 0 | 2914.336919 | 2664.338306 | 3208.135842 |
| 2021-07-03 | 0 | 2318.810952 | 2004.743839 | 2578.830978 |
| 2021-07-04 | 0 | 1957.766737 | 1657.452071 | 2174.728528 |
| 2021-07-05 | 0 | 3002.216742 | 2608.296170 | 3294.607486 |
# Gráfico intervalos de predicción
# ==============================================================================
fig = go.Figure([
go.Scatter(
name='Prediction',
x=predicciones.index,
y=predicciones['pred'],
mode='lines',
),
go.Scatter(
name='Real value',
x=datos_test.index,
y=datos_test.loc[:, 'users'],
mode='lines',
),
go.Scatter(
name='Upper Bound',
x=predicciones.index,
y=predicciones['upper_bound'],
mode='lines',
marker=dict(color="#444"),
line=dict(width=0),
showlegend=False
),
go.Scatter(
name='Lower Bound',
x=predicciones.index,
y=predicciones['lower_bound'],
marker=dict(color="#444"),
line=dict(width=0),
mode='lines',
fillcolor='rgba(68, 68, 68, 0.3)',
fill='tonexty',
showlegend=False
)
])
fig.update_layout(
title="Intervalos de predicción",
xaxis_title="Date time",
yaxis_title="users",
width=750,
height=350,
margin=dict(l=20, r=20, t=35, b=20),
hovermode="x",
legend=dict(
orientation="h",
yanchor="top",
y=1.1,
xanchor="left",
x=0.001
)
)
fig.show()
✏️ Note
Para obtener una explicación detallada de las funcionalidades de forecasting probabilística disponibles en skforecast, visite: Forecasting probabilistico con machine learning
Conclusión¶
El modelo autorregresivo basado en un regresor lineal con regularización ridge ha sido capaz de predecir el número de visitas diarias al sitio web con un MAE de 149 usuarios. El modelo se ha entrenado utilizando la mejor configuración de retardos e hiperparámetros, y se ha evaluado mediante backtesting. La inclusión de las variables exógenas basadas en fechas de calendario ha mejorado el rendimiento del modelo.
| Modelo | Variables exógenas | MAE backtest |
|---|---|---|
| BaseLine | False | 513.04 |
| Autoregressive-ridge | False | 211.98 |
| Autoregressive-ridge | True | 149.06 |
Posibles mejoras del modelo:
Incluir como predictor si el día es festivo nacional.
Utilizar un modelo autoregresivo con modelos no lineales, por ejemplo random forest o gradient boosting. Forecasting series temporales con gradient boosting: Skforecast, XGBoost, LightGBM y CatBoost.
Utilizar un modelo direct multi-step.
Información de sesión¶
import session_info
session_info.show(html=False)
----- matplotlib 3.11.0 numpy 2.4.6 pandas 2.3.3 plotly 6.9.0 session_info v1.0.1 shap 0.52.0 skforecast 0.23.0 sklearn 1.7.2 statsmodels 0.14.6 ----- IPython 9.15.0 jupyter_client 8.9.1 jupyter_core 5.9.1 ----- Python 3.13.14 | packaged by conda-forge | (main, Jun 12 2026, 09:50:25) [GCC 14.3.0] Linux-7.0.0-1008-aws-x86_64-with-glibc2.43 ----- Session information updated at 2026-07-13 22:18
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Forecasting de visitas web con machine learning por Joaquín Amat Rodrigo y Javier Escobar Ortiz, disponible bajo una licencia Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) en https://cienciadedatos.net/documentos/py37-forecasting-visitas-web-machine-learning.html
¿Cómo citar skforecast?
Si utilizas skforecast, te agradeceríamos mucho que lo cites. ¡Muchas gracias!
Zenodo:
Amat Rodrigo, Joaquin, & Escobar Ortiz, Javier. (2024). skforecast (v0.23.0). Zenodo. https://doi.org/10.5281/zenodo.8382788
APA:
Amat Rodrigo, J., & Escobar Ortiz, J. (2024). skforecast (Version 0.23.0) [Computer software]. https://doi.org/10.5281/zenodo.8382788
BibTeX:
@software{skforecast, author = {Amat Rodrigo, Joaquin and Escobar Ortiz, Javier}, title = {skforecast}, version = {0.23.0}, month = {07}, year = {2026}, license = {BSD-3-Clause}, url = {https://skforecast.org/}, doi = {10.5281/zenodo.8382788} }
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊




Este documento creado por Joaquín Amat Rodrigo y Javier Escobar Ortiz tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.