Más sobre forecasting en: cienciadedatos.net
- Forecasting series temporales con machine learning
- Modelos ARIMA y SARIMAX
- Forecasting series temporales con gradient boosting: XGBoost, LightGBM y CatBoost
- Global Forecasting: Multi-series forecasting
- Forecasting de la demanda eléctrica con machine learning
- Forecasting con deep learning
- Forecasting de visitas a página web con machine learning
- Forecasting del precio de Bitcoin
- Forecasting probabilístico
- Forecasting de demanda intermitente
- Reducir el impacto del Covid en modelos de forecasting
- Modelar series temporales con tendencia utilizando modelos de árboles

Introducción¶
Una serie temporal (time series) es una sucesión de datos ordenados cronológicamente y espaciados a intervalos iguales o desiguales. El proceso de forecasting consiste en predecir el valor futuro de una serie temporal, bien modelando la serie únicamente en función de su comportamiento pasado o empleando otras variables adicionales.
En términos generales, al crear un modelo de forecasting se utilizan datos históricos con el objetivo de obtener una representación matemática capaz de predecir futuros valores. Esta idea se fundamenta sobre una asunción muy importante, el comportamiento futuro de un fenómeno se puede explicar a partir de su comportamiento pasado. Sin embargo, esto raramente ocurre en la relaidad, o al menos, no en su totalidad. Para profundizar en esto, vease la siguiente definición:
$$Forecast = patrones + varianza\;no\;explicada$$El primer término de la ecuación hace referencia a todo aquello que tiene un carácter repetitivo a lo largo del tiempo (tendencia, estacionalidad, factores cíclicos...). El segundo término, representa todo aquello que influye en la variable respuesta pero que no está recogido (explicado) por el pasado de la serie temporal.
Cuanto mayor importancia tenga el primer término respecto al segundo, mayor será la probabilidad de exito al tratar de crear modelos de forecasting de tipo autoregresivo. A medida que el segundo término adquiere peso, se hace necesario incorporar al modelo variables adicionales (si es que existen) que ayuden a explicar el comportamiento observado.
Realizar un buen estudio del fenómeno modelado y saber reconocer en qué medida su comportamiento puede explicarse gracias a su pasado, puede ahorrar muchos esfuerzos inecesarios.
En este documento se muestra un ejemplo de cómo identificar situaciones en las que el proceso de forecasting autorregresivo no consigue resultados útiles. Como ejemplo, se intenta predecir el precio de cierre diario de Bitcoin utlizando métodos de machine learning. Se hace uso de Skforecast, una sencilla librería de Python que permite, entre otras cosas, adaptar cualquier regresor de Scikit-learn a problemas de forecasting.
Caso de uso¶

Bitcoin (₿) es una criptomoneda descentralizada que puede enviarse de un usuario a otro mediante la red bitcoin peer-to-peer sin necesidad de intermediarios. Las transacciones son verificadas y registradas en un libro de contabilidad público distribuido llamado blockchain. Los Bitcoins se crean como recompensa por un proceso conocido como minería y pueden intercambiarse por otras monedas, productos y servicios.
Aunque puedan existir diversas opiniones sobre Bitcoin, bien como un activo especulativo de alto riesgo o, por otro lado, como una reserva de valor, es innegable que este se ha convertido en uno de los activos financieros más valiosos a nivel mundial. La página web Infinite Market Cap muestra un listado de todos los activos financieros ordenados según su capitalización de mercado y, Bitcoin, a fecha de este artículo, se encuentra en el top 10 cerca de empresas mundialmente conocidas como Tesla o, incluso, de la plata, un valor refugio globalmente aceptado. El creciente interés en Bitcoin, y el mundo de las criptomonedas en general, por parte de los inversores lo convierte en un fenómeno interesante de modelar.
Se pretende generar un modelo de forecasting capaz de predecir el precio de Bitcoin. Se dispone de una serie temporal con los precios de apertura (Open), cierre (Close), máximo (High) y mínimo (Low) de Bitcoin en dólares estadounidenses (USD) desde el 2013-04-28 al 2022-01-01.
Librerias¶
# Tratamiento de datos
# ==============================================================================
import pandas as pd
import numpy as np
import datetime
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px
import seaborn as sns
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from skforecast.plot import set_dark_theme
# Modelado y Forecasting
# ==============================================================================
import skforecast
import sklearn
import lightgbm
from skforecast.recursive import ForecasterRecursive
from skforecast.model_selection import TimeSeriesFold
from skforecast.model_selection import backtesting_forecaster
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_absolute_error
# warnings
# ==============================================================================
import warnings
from skforecast.exceptions import LongTrainingWarning
warnings.filterwarnings("once")
warnings.simplefilter('ignore', category=LongTrainingWarning)
color = "\033[1m\033[38;5;208m"
print(f"{color}Versión skforecast: {skforecast.__version__}")
print(f"{color}Versión scikit-learn: {sklearn.__version__}")
print(f"{color}Version lightgbm: {lightgbm.__version__}")
print(f"{color}Versión pandas: {pd.__version__}")
print(f"{color}Versión numpy: {np.__version__}")
Versión skforecast: 0.22.0 Versión scikit-learn: 1.7.2 Version lightgbm: 4.6.0 Versión pandas: 2.3.3 Versión numpy: 2.1.3
Datos¶
Los datos utilizados contienen el historial de precios de Bitcoin desde el 2013-04-28 al 2022-01-01. El dataset contiene las siguientes columnas:
Date: fecha del registro.Open: precio de apertura, precio al que cotiza un activo, en este caso el Bitcoin, en el comienzo del día. Expresado en dólares estadounidenses (USD).High: precio máximo del día, precio más alto alcanzado por el Bitcoin en ese día, (USD).Low: precio mínimo del día, precio más bajo alcanzado por el Bitcoin en ese día, (USD).Close: precio de cierre, precio al que cotiza el Bitcoin a la finalización del día, (USD).Volume: volumen, suma de las operaciones reales realizadas durante el día, (USD).Market Cap: capitalización de mercado, es el valor total de todas las acciones de una empresa o, en el caso de Bitcoin u otra criptomoneda, de todas las monedas que hay en circulación, (USD).
Nota: el mercado de las criptomonedas es un mercado ininterrumpido, opera las 24 horas del día, los 7 días de la semana. De todas maneras, no es estrictamente necesario que el precio close coincida con el precio open del día siguiente debido a las fluctuaciones que pueda sufrir el valor de Bitcoin, o cualquier criptomoneda, durante el último segundo del día.
# Lectura de datos
# ==============================================================================
data = pd.read_csv(
"https://raw.githubusercontent.com/skforecast/skforecast-datasets/main/data/bitcoin.csv"
)
data['date'] = pd.to_datetime(data['date'])
data = data.set_index('date')
data = data.asfreq('D')
data
| open | high | low | close | volume | market cap | |
|---|---|---|---|---|---|---|
| date | ||||||
| 2013-04-28 | 128.000100 | 128.000100 | 128.000100 | 128.000100 | 0.000000e+00 | 1.418304e+09 |
| 2013-04-29 | 134.444400 | 135.980000 | 132.100000 | 134.210000 | 0.000000e+00 | 1.488338e+09 |
| 2013-04-30 | 134.444000 | 147.488000 | 134.000000 | 144.540000 | 0.000000e+00 | 1.549501e+09 |
| 2013-05-01 | 144.000000 | 146.930000 | 134.050000 | 139.000000 | 0.000000e+00 | 1.578685e+09 |
| 2013-05-02 | 139.000000 | 139.890000 | 107.720000 | 116.990000 | 0.000000e+00 | 1.422546e+09 |
| ... | ... | ... | ... | ... | ... | ... |
| 2021-12-28 | 50787.263830 | 51950.912600 | 50459.263641 | 50650.171445 | 4.695844e+10 | 9.655866e+11 |
| 2021-12-29 | 50667.988338 | 50667.988338 | 47411.717237 | 47637.888400 | 5.939821e+10 | 9.241336e+11 |
| 2021-12-30 | 47547.865500 | 48112.021472 | 46272.662981 | 46408.302671 | 8.826973e+10 | 8.998872e+11 |
| 2021-12-31 | 46430.481224 | 47876.491839 | 46077.722276 | 47161.009200 | 1.229248e+11 | 8.907742e+11 |
| 2022-01-01 | 47139.359000 | 48505.999700 | 45712.566592 | 46304.949594 | 7.810027e+10 | 8.945653e+11 |
3171 rows × 6 columns
Al establecer una frecuencia con el método asfreq(), Pandas completa los huecos que puedan existir en la serie temporal con el valor de Null con el fin de asegurar la frecuencia indicada. Por ello, se debe comprobar si han aparecido missing values tras esta transformación.
print(f'Número de filas con missing values: {data.isnull().any(axis=1).mean()}')
Número de filas con missing values: 0.0
Halving del Bitcoin como variable exógena¶
El Halving es un evento programado y forma parte del diseño y funcionamiento de algunas criptomonedas. Los mineros se dedican a validar los bloques de transacciones de la red, en este caso Bitcoin, y, cada vez que lo logran, reciben como recompensa una cantidad de esa moneda digital. Esta cantidad es fija pero solo durante un tiempo.
En la blockchain de Bitcoin, cada vez que se añaden 210.000 bloques ocurre el cambio de recompensa. Este hecho, denominado como halving, se produce aproximadamente cada 4 años y reduce a la mitad las monedas que reciben los mineros.
En la historia de Bitcoin han existido 3 halvings. Cuando se lanzó la minería de Bitcoin, los mineros recibían 50 BTC al extraer con éxito un bloque. En 2012 esta recompensa se redujo a 25 BTC, en 2016 bajó a 12,5 BTC, y en 2020 a 6,25 BTC, después del tercer halving. Por lo general, cada halving ha tenido un impacto en el precio aunque no necesariamente ha sido en el corto plazo.
Se pretende utilizar los días restantes para el próximo halving y sus recompensas de minado como variables exógenas para predecir el precio de Bitcoin. Se calcula que el próximo halving ocurrirá aproximadamente en 2024 aunque se desconoce su fecha exacta. Para estimarla, se toman los bloques restantes a fecha de 2022-01-14 de la página web Coinmarketcap, 121.400, y se utiliza el promedio de los bloques de la red Bitcoin minados por día, 144 (tiempo de bloque promedio $\approx$ 10 minutos).
Nota: Al incorporar datos predichos como una variable exógena, se introduce, dado que se trata de predicciones, su error en el modelo de forecasting.
# Dict con la info de los halvings del Bitcoin
# ==============================================================================
btc_halving = {
"halving": [0, 1, 2, 3, 4],
"date": ["2009-01-03", "2012-11-28", "2016-07-09", "2020-05-11", np.nan],
"reward": [50, 25, 12.5, 6.25, 3.125],
"halving_block_number": [0, 210000, 420000, 630000, 840000],
}
# Cálculo siguiente halving
# Se toma como base de partida los bloques restantes según la web
# coinmarketcap.com para el próximo halving a fecha de 2022-01-14
# ==============================================================================
bloques_restantes = 121400
bloques_por_dia = 144
dias = bloques_restantes / bloques_por_dia
next_halving = pd.to_datetime('2022-01-14', format='%Y-%m-%d') + datetime.timedelta(days=dias)
next_halving = next_halving.replace(microsecond=0, second=0, minute=0, hour=0)
next_halving = next_halving.strftime('%Y-%m-%d')
btc_halving['date'][-1] = next_halving
print(f'El próximo halving ocurrirá aproximadamente el: {next_halving}')
El próximo halving ocurrirá aproximadamente el: 2024-05-06
# Incluir recompensas y cuenta regresiva para próximo halving en el dataset
# ==============================================================================
data["reward"] = np.nan
data["countdown_halving"] = np.nan
for i in range(len(btc_halving["halving"]) - 1):
# Fecha inicial y final de cada halving
if btc_halving["date"][i] < data.index.min().strftime("%Y-%m-%d"):
start_date = data.index.min().strftime("%Y-%m-%d")
else:
start_date = btc_halving["date"][i]
end_date = btc_halving["date"][i + 1]
mask = (data.index >= start_date) & (data.index < end_date)
# Rellenar columna 'reward' con las recompensas de minería
data.loc[mask, "reward"] = btc_halving["reward"][i]
# Rellenar columna 'countdown_halving' con los días restantes
time_to_next_halving = pd.to_datetime(end_date) - pd.to_datetime(start_date)
data.loc[mask, "countdown_halving"] = np.arange(time_to_next_halving.days)[::-1][
: mask.sum()
]
# Comprobar que se han creado los datos correctamente
# ==============================================================================
print("Segundo halving:", btc_halving["date"][2])
display(data.loc["2016-07-08":"2016-07-09"])
print("")
print("Tercer halving:", btc_halving["date"][3])
display(data.loc["2020-05-10":"2020-05-11"])
print("")
print("Próximo halving:", btc_halving["date"][4])
data.tail(2)
Segundo halving: 2016-07-09
| open | high | low | close | volume | market cap | reward | countdown_halving | |
|---|---|---|---|---|---|---|---|---|
| date | ||||||||
| 2016-07-08 | 677.331 | 682.432 | 611.834 | 639.667 | 1.892361e+08 | 1.015055e+10 | 25.0 | 0.0 |
| 2016-07-09 | 640.562 | 666.707 | 636.467 | 666.707 | 2.061508e+08 | 1.020561e+10 | 12.5 | 1401.0 |
Tercer halving: 2020-05-11
| open | high | low | close | volume | market cap | reward | countdown_halving | |
|---|---|---|---|---|---|---|---|---|
| date | ||||||||
| 2020-05-10 | 9814.400817 | 9900.431521 | 9559.705894 | 9570.005988 | 3.675906e+10 | 1.786858e+11 | 12.50 | 0.0 |
| 2020-05-11 | 9554.216377 | 9554.216377 | 8388.959555 | 8745.152545 | 4.909643e+10 | 1.598261e+11 | 6.25 | 1455.0 |
Próximo halving: 2024-05-06
| open | high | low | close | volume | market cap | reward | countdown_halving | |
|---|---|---|---|---|---|---|---|---|
| date | ||||||||
| 2021-12-31 | 46430.481224 | 47876.491839 | 46077.722276 | 47161.009200 | 1.229248e+11 | 8.907742e+11 | 6.25 | 856.0 |
| 2022-01-01 | 47139.359000 | 48505.999700 | 45712.566592 | 46304.949594 | 7.810027e+10 | 8.945653e+11 | 6.25 | 855.0 |
Exploración gráfica¶
Cuando se quiere generar un modelo de forecasting, es importante representar los valores de la serie temporal. Esto permite identificar patrones tales como tendencias y estacionalidad.
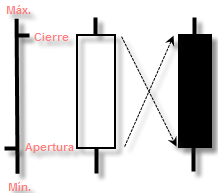
Gráfico de velas¶
Un gráfico de velas japonesas es un tipo de gráfico muy utilizado en el mundo del análisis técnico. El cuerpo de la vela indica la variación entre el precio de apertura y cierre, para un periodo determinado, mientras que los pelos o sombras indican los valores mínimo y máximo alcanzados durante ese periodo.
# Gráfico de velas japonesas interactivo con Plotly
# ==============================================================================
candlestick = go.Candlestick(
x=data.index,
open=data.open,
close=data.close,
low=data.low,
high=data.high,
)
fig = go.Figure(data=[candlestick])
fig.update_layout(
width=750,
height=350,
title=dict(text="<b>Chart Bitcoin/USD</b>", font=dict(size=20)),
yaxis_title=dict(text="Precio (USD)", font=dict(size=15)),
margin=dict(l=10, r=20, t=80, b=20),
shapes=[
dict(
x0=btc_halving["date"][2],
x1=btc_halving["date"][2],
y0=0,
y1=1,
xref="x",
yref="paper",
line_width=2,
),
dict(
x0=btc_halving["date"][3],
x1=btc_halving["date"][3],
y0=0,
y1=1,
xref="x",
yref="paper",
line_width=2,
),
dict(
x0=btc_halving["date"][4],
x1=btc_halving["date"][4],
y0=0,
y1=1,
xref="x",
yref="paper",
line_width=2,
),
],
annotations=[
dict(
x=btc_halving["date"][2],
y=1,
xref="x",
yref="paper",
showarrow=False,
xanchor="left",
text="Segundo halving",
),
dict(
x=btc_halving["date"][3],
y=1,
xref="x",
yref="paper",
showarrow=False,
xanchor="left",
text="Tercer halving",
),
dict(
x=btc_halving["date"][4],
y=1,
xref="x",
yref="paper",
showarrow=False,
xanchor="left",
text="Cuarto halving",
),
],
xaxis_rangeslider_visible=False,
)
fig.show()
Distribución de los datos¶
Se muestra la distribución del precio de cierre de Bitcoin, variable close.
# Distribución KDE del precio de cierre del Bitcoin
# ==============================================================================
set_dark_theme()
fig, ax = plt.subplots(figsize=(6, 3))
p = sns.kdeplot(data=data, x="close", linewidth=3, ax=ax)
r = sns.rugplot(data=data, x="close", ax=ax, height=-0.03, clip_on=False)
p.set(xlim=(0, None))
p.set_title("KDE Bitcoin Precio Close", fontsize=15)
p.set_xlabel("Precio (USD)");

En los datos de estudio se observa una distribución mayoritaria de precios por debajo de los 20.000 (USD). Esta etapa corresponde al periodo entre el año 2013 y septiembre de 2020. En cambio, desde 2021, el precio se ha situado en la zona de los 35.000 - 67.500 (USD).
Tratar de modelar una serie temporal con una distribución muy asimétrica y distintos órdenes de magnitud a lo largo del tiempo puede ser complicado. Una estrategia, para tratar de minimizar estos problemas, es modelar los cambios (deltas) en lugar de los valores directos. Esto se podría simplificar aún más llevándolo al punto de indicar únicamente si el precio aumenta o disminuye respecto al día anterior.
Nota: cuando una distribución es asimétrica, modelar los deltas en lugar del precio puede conseguir una distribución más simétrica.
Precio por año¶
# Se localizan los datos correspondientes para cada año
# ==============================================================================
years = list(data.index.year.unique())
df_plot = pd.DataFrame()
for year in years:
year_open = data.loc[data.index.year == year, "open"].iloc[0]
year_close = data.loc[data.index.year == year, "close"].iloc[-1]
year_low = data.loc[data.index.year == year, "low"].min()
year_high = data.loc[data.index.year == year, "high"].max()
df_plot[year] = pd.Series([year_open, year_close, year_low, year_high])
df_plot = df_plot.T
df_plot = df_plot.set_axis(["open", "close", "low", "high"], axis=1)
# Se calcula el % de cambio entre el open y el close del año
# ==============================================================================
df_plot["year_change"] = 100 * (df_plot["close"] - df_plot["open"]) / df_plot["open"]
df_plot.head(3)
| open | close | low | high | year_change | |
|---|---|---|---|---|---|
| 2013 | 128.0001 | 756.130 | 65.526 | 1156.140 | 490.726101 |
| 2014 | 760.3200 | 310.610 | 289.296 | 1017.120 | -59.147464 |
| 2015 | 310.7370 | 426.371 | 171.510 | 495.562 | 37.212820 |
# Se crea una lista de dicts con las anotaciones de % de cambio para el gráfico
# ==============================================================================
annotations_list = []
max_high = df_plot["high"].max()
for year in years:
df_aux = df_plot.loc[df_plot.index == year,]
loc_x = pd.to_datetime(df_aux.index[0], format="%Y")
loc_y = df_aux["high"].values[0] / max_high + 0.05
text = "{:.1f}%".format(df_aux["year_change"].values[0])
annotation = dict(
x=loc_x,
y=loc_y,
xref="x",
yref="paper",
showarrow=False,
xanchor="center",
text=text,
)
annotations_list.append(annotation)
# Gráfico de velas japonesas anual interactivo con Plotly
# ==============================================================================
candlestick = go.Candlestick(
x=pd.to_datetime(df_plot.index, format="%Y"),
open=df_plot.open,
close=df_plot.close,
low=df_plot.low,
high=df_plot.high,
)
fig = go.Figure(data=[candlestick])
fig.update_layout(
width=750,
height=350,
title=dict(text="<b>Chart Bitcoin/USD por año</b>", font=dict(size=20)),
yaxis_title=dict(text="Precio (USD)", font=dict(size=13)),
margin=dict(l=0, r=20, t=55, b=20),
xaxis_rangeslider_visible=False,
annotations=annotations_list,
)
fig.show()
Estacionalidad anual, mensual y semanal¶
# Se localizan los datos correspondientes para cada mes
# ==============================================================================
years = list(data.index.year.unique())
df_plot = pd.DataFrame()
for year in years:
for mes in range(12):
start_date = pd.to_datetime(f"{year}-{mes+1}-01", format="%Y-%m-%d")
end_date = start_date + pd.offsets.MonthBegin()
mask = (data.index >= start_date) & (data.index < end_date)
if not data.loc[mask, :].empty:
month_open = data.loc[mask, "open"].iloc[0]
month_close = data.loc[mask, "close"].iloc[-1]
month_low = data.loc[mask, "low"].min()
month_high = data.loc[mask, "high"].max()
serie = pd.Series([month_open, month_close, month_low, month_high])
df_aux = pd.DataFrame(serie, columns=[f"{str(mes+1).zfill(2)}-{year}"])
if df_plot.empty:
df_plot = df_aux.copy()
else:
df_plot = pd.concat([df_plot, df_aux], axis=1)
df_plot = df_plot.T
df_plot = df_plot.set_axis(["open", "close", "low", "high"], axis=1)
# Gráfico boxplot para estacionalidad anual
# ==============================================================================
df_plot["mes"] = pd.to_datetime(df_plot.index, format="%m-%Y").month
# fig 1 boxplot de los meses
fig1 = px.box(df_plot.sort_values("mes"), x="mes", y="close")
# fig 2 line con datos de la mediana de cada mes
df_median = pd.DataFrame(df_plot.groupby("mes")["close"].median()).reset_index()
fig2 = px.line(df_median, x="mes", y="close", markers=True)
fig = go.Figure(data=fig1.data + fig2.data)
fig.update_layout(
width=650,
height=350,
title=dict(text="<b>BTC Precio por mes</b>", font=dict(size=20)),
yaxis_title=dict(text="Precio (USD)", font=dict(size=13)),
xaxis=dict(tickmode="linear"),
xaxis_title=dict(text="mes", font=dict(size=13)),
margin=dict(l=0, r=20, t=55, b=20),
)
fig.show()
# Gráfico boxplot para estacionalidad mensual
# ==============================================================================
data["dia_mes"] = pd.Series(data.index).dt.day.values
# fig 1 boxplot de los días del mes
fig1 = px.box(data.sort_values("dia_mes"), x="dia_mes", y="close")
# fig 2 line con datos de la mediana de los días del mes
df_median = pd.DataFrame(data.groupby("dia_mes")["close"].median()).reset_index()
fig2 = px.line(df_median, x="dia_mes", y="close", markers=True)
fig = go.Figure(data=fig1.data + fig2.data)
fig.update_layout(
width=750,
height=350,
title=dict(text="<b>BTC Precio por día del mes</b>", font=dict(size=20)),
yaxis_title=dict(text="Precio (USD)", font=dict(size=13)),
xaxis=dict(tickmode="linear", tickangle=0, range=[0.5, 31.5]),
xaxis_title=dict(text="día", font=dict(size=13)),
margin=dict(l=0, r=20, t=55, b=20),
)
fig.show()
# Gráfico boxplot para estacionalidad semanal
# ==============================================================================
data["dia_semana"] = data.index.day_of_week + 1
# fig 1 boxplot de los días de la semana
fig1 = px.box(
data.sort_values("dia_semana"),
x="dia_semana",
y="close"
)
# fig 2 line con datos de la mediana los días de la semana
df_median = pd.DataFrame(data.groupby("dia_semana")["close"].median()).reset_index()
fig2 = px.line(
df_median,
x="dia_semana",
y="close",
markers=True
)
fig = go.Figure(data=fig1.data + fig2.data)
fig.update_layout(
width=600,
height=300,
title=dict(text="<b>BTC Precio por día de la semana</b>", font=dict(size=20)),
yaxis_title=dict(text="Precio (USD)", font=dict(size=13)),
xaxis=dict(tickmode="linear"),
xaxis_title=dict(text="día de la semana", font=dict(size=13)),
margin=dict(l=0, r=20, t=55, b=20),
)
fig.show()
Por lo general, una serie temporal con patrón autoregresivo presenta un carácter repetitivo a lo largo del tiempo (tendencia, estacionalidad, factores cíclicos...). Respecto al Bitcoin, se puede apreciar una cierta estacionalidad anual al final y principio del año con variaciones más grandes en el precio. En cambio, no aparece ningún tipo de estacionalidad en los intervalos mensual y semanal, se tienen distribuciones muy similares.
Gráficos de autocorrelación¶
# Gráfico autocorrelación
# ==============================================================================
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
axes = axes.flat
plot_acf(data.close, ax=axes[0], linewidth = 1, lags=100, fft=True)
axes[0].set_ylim(-1.1, 1.1)
plot_pacf(data.close, ax=axes[1], lags=20, method='burg', linewidth = 1)
axes[1].set_ylim(-1.1, 1.1)
plt.show();

Los gráficos de autocorrelación indican que el lag 1 es el único que está correlacionado con el lag 0. Los siguientes lags no superan el umbral de significancia.
Baseline - Simulación del paseo aleatorio (Random Walk)¶
A la hora de generar un modelo predictivo es conveniente identificar un modelo base, o baseline, sobre el que ir comparando cada una de las iteraciones o modelos propuestos. En el caso de las finanzas, acorde a la teoría del paseo aleatorio o Random Walk, los precios de mercado se comportan de manera aleatoria y no dependiente de su serie temporal. De esta manera, la mejor estimación para el valor $t_{n+1}$ es el valor $t_{n}$ más un cambio impredecible.
Aunque se dispone de una serie temporal amplia, esta presenta periodos con precios muy diferenciados como se ha podido determinar en la exploración gráfica. Se opta por utilizar solo los dos últimos años de datos.
# Selección fechas train-test
# ==============================================================================
inicio_train = '2020-01-01 00:00:00'
fin_train = '2021-06-30 23:59:59'
print(f"Serie temporal completa : {data.index.min()} --- {data.index.max()} (n={len(data)})")
print(f"Fechas train : {data.loc[inicio_train:fin_train].index.min()} --- {data.loc[inicio_train:fin_train].index.max()} (n={len(data.loc[inicio_train:fin_train])})")
print(f"Fechas test : {data.loc[fin_train:].index.min()} --- {data.loc[fin_train:].index.max()} (n={len(data.loc[fin_train:])})")
Serie temporal completa : 2013-04-28 00:00:00 --- 2022-01-01 00:00:00 (n=3171) Fechas train : 2020-01-01 00:00:00 --- 2021-06-30 00:00:00 (n=547) Fechas test : 2021-07-01 00:00:00 --- 2022-01-01 00:00:00 (n=185)
Como se ha mencionado anteriormente, la teoría del paseo aleatorio sugiere que la mejor estimación para el valor $t_{n+1}$ es el valor $t_{n}$ más un cambio impredecible. De esta manera, el modelo más sencillo posible, y el cual se emplea como base, es aquel que simplemente utiliza el valor de $t_{n}$ como predicción para el valor $t_{n+1}$.
# Simulación Random Walk
# ==============================================================================
df_rw = data[['close']].copy()
df_rw['pred_close'] = df_rw['close'].shift(1)
# Error de test
# ==============================================================================
y_true = df_rw.loc[fin_train:, 'close']
y_pred = df_rw.loc[fin_train:, 'pred_close']
metrica = mean_absolute_error(y_true, y_pred)
print(f'Error de test: {metrica}')
display(df_rw.loc[fin_train:,].head(4))
Error de test: 1260.3677521425916
| close | pred_close | |
|---|---|---|
| date | ||
| 2021-07-01 | 35060.428966 | 35840.386468 |
| 2021-07-02 | 33628.670000 | 35060.428966 |
| 2021-07-03 | 33846.007087 | 33628.670000 |
| 2021-07-04 | 34698.303129 | 33846.007087 |
# Gráfico
# ==============================================================================
fig, ax = plt.subplots(figsize=(8, 4))
df_rw.loc[fin_train:, "close"].plot(ax=ax, linewidth=2, label="Datos Test")
df_rw.loc[fin_train:, "pred_close"].plot(ax=ax, linewidth=2, label="Pred Test")
ax.set_title("Random Walk (Datos Test)")
ax.set_ylabel("Precio (USD)")
ax.legend();

# DataFrame errores test modelos
# ==============================================================================
df_errores = pd.DataFrame({
"modelo": "Base - Random Walk",
"lags": 1,
"error_test": metrica,
"variables_exog": False,
},
index=[0],
)
df_errores
| modelo | lags | error_test | variables_exog | |
|---|---|---|---|---|
| 0 | Base - Random Walk | 1 | 1260.367752 | False |
El error del modelo en la partición de test es de 1260.37. En los siguientes apartados, se pretende generar un modelo capaz de reducir este error.
Forecaster Autorregresivo¶
Para intentar modelar el precio de Bitcoin se utilia un Forecaster Autorregresivo (ForecasterRecursive) con un regresor LightGBM, una implementación del algoritmo de Gradient Boosting desarrollada por Microsoft que suele conseguir excelentes resultados.
Los estudios anteriores muestran una ausencia de autocorrelación más allá del primer lag. Una forma de verificarlo es entrenar varios modelos con una cantidad creciente de lags y comprobar si el error no se reduce. Esta aproximación se puede realizar mediante backtesting utilizando steps = 1 (predecir únicamente el siguiente valor de la serie, $t_{n+1}$) para reproducir la metodología del modelo Random Walk.
# Backtest forecasters con diferentes lags
# ==============================================================================
lags = [1, 7, 30]
metricas = []
predicciones_list = []
for lag in lags:
# Crear forecaster
forecaster = ForecasterRecursive(
estimator = LGBMRegressor(random_state=123, verbose=-1),
lags = lag,
transformer_y = None
)
# Backtest test data 1 step
cv = TimeSeriesFold(
steps = 1,
initial_train_size = len(data.loc[inicio_train:fin_train,]),
fixed_train_size = True,
refit = True,
)
metrica, predicciones = backtesting_forecaster(
forecaster = forecaster,
y = data.loc[inicio_train:, 'close'],
cv = cv,
metric = 'mean_absolute_error',
verbose = False,
show_progress = True,
)
metricas.append(metrica.at[0, 'mean_absolute_error'])
predicciones_list.append(predicciones)
# Gráfico
# ==============================================================================
fig, ax = plt.subplots(figsize=(8, 4))
data.loc[fin_train:, 'close'].plot(ax=ax, linewidth=2, label='Datos Test')
# Plot predicciones test para diferentes lags
for predicciones, lag in zip(predicciones_list, lags):
predicciones = predicciones.rename(columns={'pred': f'Pred test, {lag} lags'})
predicciones[f'Pred test, {lag} lags'].plot(ax=ax)
ax.set_title('Close Price Real vs Predicciones (Datos Test)')
ax.set_ylabel('Precio (USD)')
ax.legend();

# DataFrame errores de test modelos
# ==============================================================================
modelo = 'LGBMRegressor'
df_errores = pd.concat([
df_errores,
pd.DataFrame({
'modelo': modelo,
'lags': lags,
'error_test': metricas,
'variables_exog': False
})
]).reset_index(drop=True)
df_errores.sort_values(by='error_test')
| modelo | lags | error_test | variables_exog | |
|---|---|---|---|---|
| 0 | Base - Random Walk | 1 | 1260.367752 | False |
| 1 | LGBMRegressor | 1 | 1527.440787 | False |
| 2 | LGBMRegressor | 7 | 1546.268058 | False |
| 3 | LGBMRegressor | 30 | 1561.058347 | False |
Los errores de test (los cuales reflejan cómo de bien generaliza cada modelo) demuestran que ninguno de los modelos mejora el baseline a pesar de que se incorpore más información del pasado (número de lags). En vista de los resultados, se intentan otras alternativas como es la incorporación de variables exógenas a la serie.
Forecaster con variables exógenas¶
Además de utilizar predictores autorregresivos generados a partir del pasado de la propia variable respuesta, es posible añadir otras variables exógenas, cuyo valor a futuro se conoce, con el fin de mejorar la predicción. Algunos ejemplos típicos son:
Festivos (local, nacional...)
Mes del año
Día de la semana
Hora del día
Para este caso, se decide utilizar las variables resultantes del apartado sobre el halving del Bitcoin y, tras el estudio de la estacionalidad, el mes del año.
Nota: Las variables reward y mes, aunque codificadas como números, son categóricas, por lo que conviene cambiar el tipo con el que están almacenadas. Dado que estas variables no tienen muchos niveles se recurre a la estrategia de One Hot Encoding para incorporarlas al modelo.
# One hot encoding de las variables categóricas
# ==============================================================================
data['mes'] = data.index.month
data = pd.get_dummies(data, columns=['reward', 'mes'], dtype=int)
data.head(2)
| open | high | low | close | volume | market cap | countdown_halving | dia_mes | dia_semana | reward_6.25 | ... | mes_3 | mes_4 | mes_5 | mes_6 | mes_7 | mes_8 | mes_9 | mes_10 | mes_11 | mes_12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2013-04-28 | 128.0001 | 128.0001 | 128.0001 | 128.0001 | 0.0 | 1.418304e+09 | 1167.0 | 28 | 7 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2013-04-29 | 134.4444 | 135.9800 | 132.1000 | 134.2100 | 0.0 | 1.488338e+09 | 1166.0 | 29 | 1 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
2 rows × 24 columns
# Se seleccionan todas las variables exógenas, incluidas las obtenidas al hacer
# el one hot encoding
# ==============================================================================
exog = [column for column in data.columns if column.startswith(('reward', 'mes'))]
exog.extend(['countdown_halving'])
exog
['reward_6.25', 'reward_12.5', 'reward_25.0', 'mes_1', 'mes_2', 'mes_3', 'mes_4', 'mes_5', 'mes_6', 'mes_7', 'mes_8', 'mes_9', 'mes_10', 'mes_11', 'mes_12', 'countdown_halving']
# Backtest forecaster con variables exógenas
# ==============================================================================
forecaster = ForecasterRecursive(
estimator = LGBMRegressor(random_state=123, verbose=-1),
lags = 1,
transformer_y = None,
transformer_exog = None
)
# Backtest test data 1 step
metrica, predicciones = backtesting_forecaster(
forecaster = forecaster,
y = data.loc[inicio_train:, 'close'],
exog = data.loc[inicio_train:, exog],
cv = cv,
metric = 'mean_absolute_error',
verbose = False,
show_progress = True
)
# Gráfico
# ==============================================================================
fig, ax = plt.subplots(figsize=(8, 4))
data.loc[fin_train:, 'close'].plot(ax=ax, linewidth=2, label='Datos Test')
# Plot predicciones 1 lag sin variables exógenas
predicciones_no_exog = predicciones_list[0].rename(columns={'pred': 'Pred test, 1 lag'})
predicciones_no_exog['Pred test, 1 lag'].plot(ax=ax)
# Plot predicciones 1 lag con variables exógenas
predicciones_exog = predicciones.rename(columns={'pred': 'Pred test, 1 lag con exog'})
predicciones_exog['Pred test, 1 lag con exog'].plot(ax=ax)
ax.set_title('Close Price Real vs Predicciones (Datos Test)')
ax.set_ylabel('Precio (USD)')
ax.legend();

# DataFrame errores de test modelos
# ==============================================================================
modelo = 'LGBMRegressor'
df_errores = pd.concat([
df_errores,
pd.DataFrame({
'modelo': modelo,
'lags': lags,
'error_test': metricas,
'variables_exog': True
})
]).reset_index(drop=True)
df_errores.sort_values(by='error_test')
| modelo | lags | error_test | variables_exog | |
|---|---|---|---|---|
| 0 | Base - Random Walk | 1 | 1260.367752 | False |
| 1 | LGBMRegressor | 1 | 1527.440787 | False |
| 4 | LGBMRegressor | 1 | 1527.440787 | True |
| 2 | LGBMRegressor | 7 | 1546.268058 | False |
| 5 | LGBMRegressor | 7 | 1546.268058 | True |
| 3 | LGBMRegressor | 30 | 1561.058347 | False |
| 6 | LGBMRegressor | 30 | 1561.058347 | True |
Aun incorporando variables exógenas, el modelo no consigue mejorar el baseline (random walk).
Conclusiones¶
Como se ha demostrado en este documento, el precio de Bitcoin no sigue un patrón autorregresivo, la mejor estimación para el valor $t_{n+1}$ es el valor $t_{n}$ más un cambio impredecible. La identificación temprana de la ausencia de esta correlación mediante análisis descriptivo evita esfuerzos de modelado innecesarios.
Cuando se dispone de una serie temporal con ausencia de autocorrelación se deben buscar variables exógenas capaces de ayudar en el problema. Por ejemplo, si se intentase predecir el precio de Bitcoin a corto plazo (horas) podrían emplearse como variables exógenas el sentimiento del mercado mediante el análisis de tweets, impacto de los denominados key opinion leaders, análisis de noticias más relevantes, etc.
Utilizar modelos de machine learning en problemas de forecasting es muy sencillo gracias a las funcionalidades ofrecidas por Skforecast.
Información de sesión¶
import session_info
session_info.show(html=False)
----- lightgbm 4.6.0 matplotlib 3.10.8 numpy 2.1.3 pandas 2.3.3 plotly 6.7.0 seaborn 0.13.2 session_info v1.0.1 skforecast 0.22.0 sklearn 1.7.2 statsmodels 0.14.6 ----- IPython 9.12.0 jupyter_client 8.8.0 jupyter_core 5.9.1 ----- Python 3.12.13 | packaged by conda-forge | (main, Mar 5 2026, 16:36:12) [MSC v.1944 64 bit (AMD64)] Windows-11-10.0.26200-SP0 ----- Session information updated at 2026-05-03 13:26
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Predicción del precio de Bitcoin con Python, cuando el pasado no se repite por Joaquín Amat Rodrigo y Javier Escobar Ortiz, disponible bajo una licencia Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) en https://www.cienciadedatos.net/documentos/py41-forecasting-criptomoneda-bitcoin-machine-learning-python.html
¿Cómo citar skforecast?
Si utilizas skforecast, te agradeceríamos mucho que lo cites. ¡Muchas gracias!
Zenodo:
Amat Rodrigo, Joaquin, & Escobar Ortiz, Javier. (2024). skforecast (v0.22.0). Zenodo. https://doi.org/10.5281/zenodo.8382788
APA:
Amat Rodrigo, J., & Escobar Ortiz, J. (2024). skforecast (Version 0.22.0) [Computer software]. https://doi.org/10.5281/zenodo.8382788
BibTeX:
@software{skforecast, author = {Amat Rodrigo, Joaquin and Escobar Ortiz, Javier}, title = {skforecast}, version = {0.22.0}, month = {04}, year = {2026}, license = {BSD-3-Clause}, url = {https://skforecast.org/}, doi = {10.5281/zenodo.8382788} }
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊


{kind=link}


Este documento creado por Joaquín Amat Rodrigo y Javier Escobar Ortiz tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.