Más sobre forecasting en: cienciadedatos.net
- Forecasting series temporales con machine learning
- Modelos ARIMA y SARIMAX
- Forecasting series temporales con gradient boosting: XGBoost, LightGBM y CatBoost
- Global Forecasting: Multi-series forecasting
- Forecasting de la demanda eléctrica con machine learning
- Forecasting con deep learning
- Forecasting de visitas a página web con machine learning
- Forecasting del precio de Bitcoin
- Forecasting probabilístico
- Forecasting de demanda intermitente
- Reducir el impacto del Covid en modelos de forecasting
- Modelar series temporales con tendencia utilizando modelos de árboles

Modelos de forecasting globales¶
En los modelos de series individuales (Local Forecasting Model), una única serie temporal se modela como una combinación lineal o no lineal de sus valores pasados y, opcionalmente, variables exógenas. Aunque este método proporciona una comprensión exhaustiva de cada serie, su escalabilidad puede verse comprometida cuando se dispone de un gran número de series.
Los modelos globales multiserie (Global Forecasting Model) consisten en un único modelo que tiene en cuenta varias series temporales de forma simultánea. Intentan captar los patrones comunes que rigen las series, mitigando así el ruido potencial que pueda introducir cada serie. Este enfoque es eficiente desde el punto de vista computacional, es fácil de mantener y puede conseguir mayor generalización, aunque potencialmente a costa de sacrificar cierta resolución individual. Se pueden distinguir dos estrategias de modelos de previsión global: Múltiples series temporales independientes y Múltiples series temporales dependientes.
Ventajas de los modelos multiseries
Es más fácil mantener y controlar un solo modelo que varios.
Dado que todas las series temporales se combinan durante el entrenamiento, cuando las series sean cortas (pocos datos) el modelo tendrá una mayor capacidad de aprendizaje al disponer de más observaciones.
Al combinar múltiples series temporales, el modelo puede aprender patrones más generalizables.
Desventajas de los modelos multiseries
Si las series no siguen la misma dinámica interna, el modelo puede aprender un patrón que no represente a ninguna de ellas.
Las series pueden enmascararse unas a otras, por lo que el modelo puede no predecirlas todas con el mismo rendimiento.
Es más exigente desde el punto de vista computacional (tiempo y recursos) entrenar y realizar backtesting de un modelo grande que de varios pequeños.
Múltiples series temporales independientes
En este escenario, cada serie temporal es independiente de las demás o, dicho de otro modo, los valores pasados de una serie no se utilizan como predictores de las otras series. ¿Por qué es útil entonces modelar todo junto? Aunque las series no dependen unas de otras, pueden seguir el mismo patrón intrínseco en cuanto a sus valores pasados y futuros. Por ejemplo, en una misma tienda, las ventas de los productos A y B pueden no estar relacionadas, pero siguen la misma dinámica, la de la tienda.
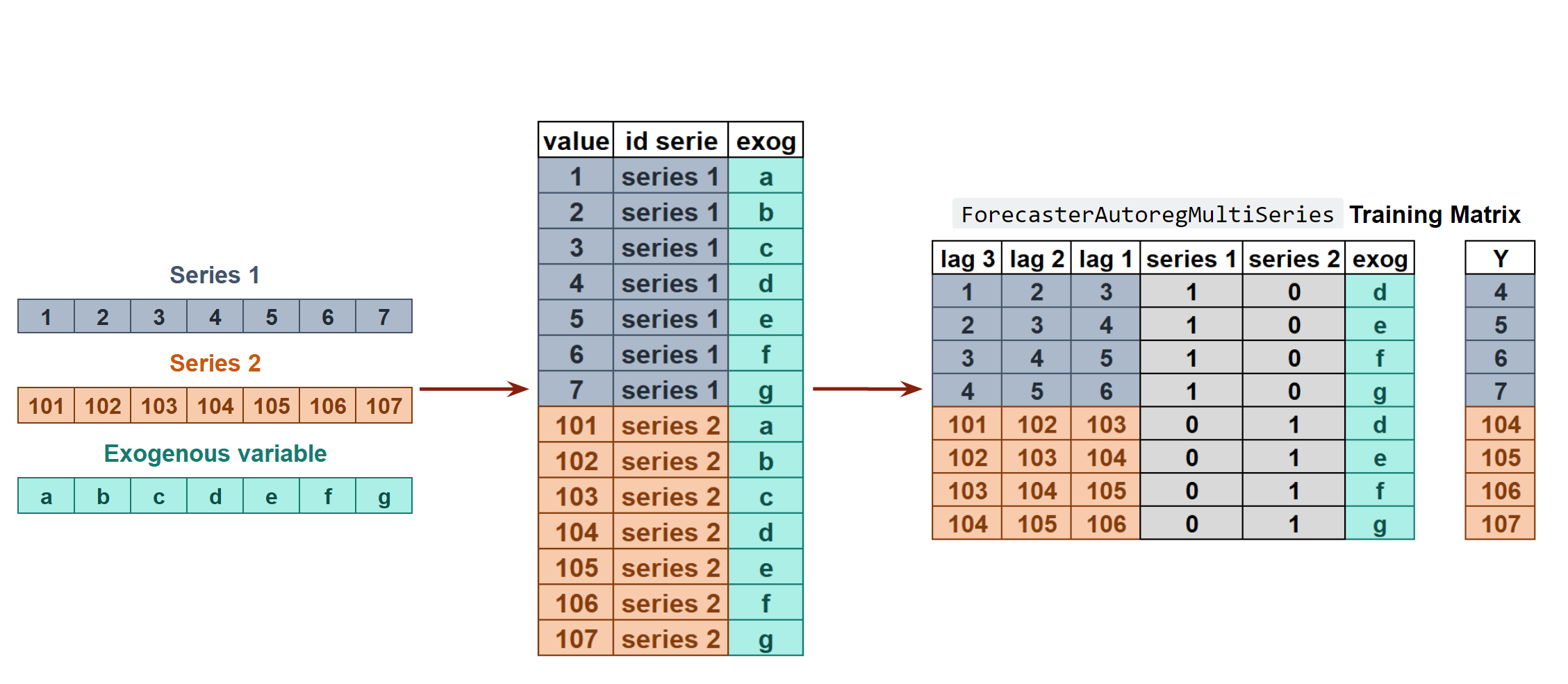
Para predecir los siguientes n steps, se sigue una estrategia recurisva, recursive multi-step forecasting.
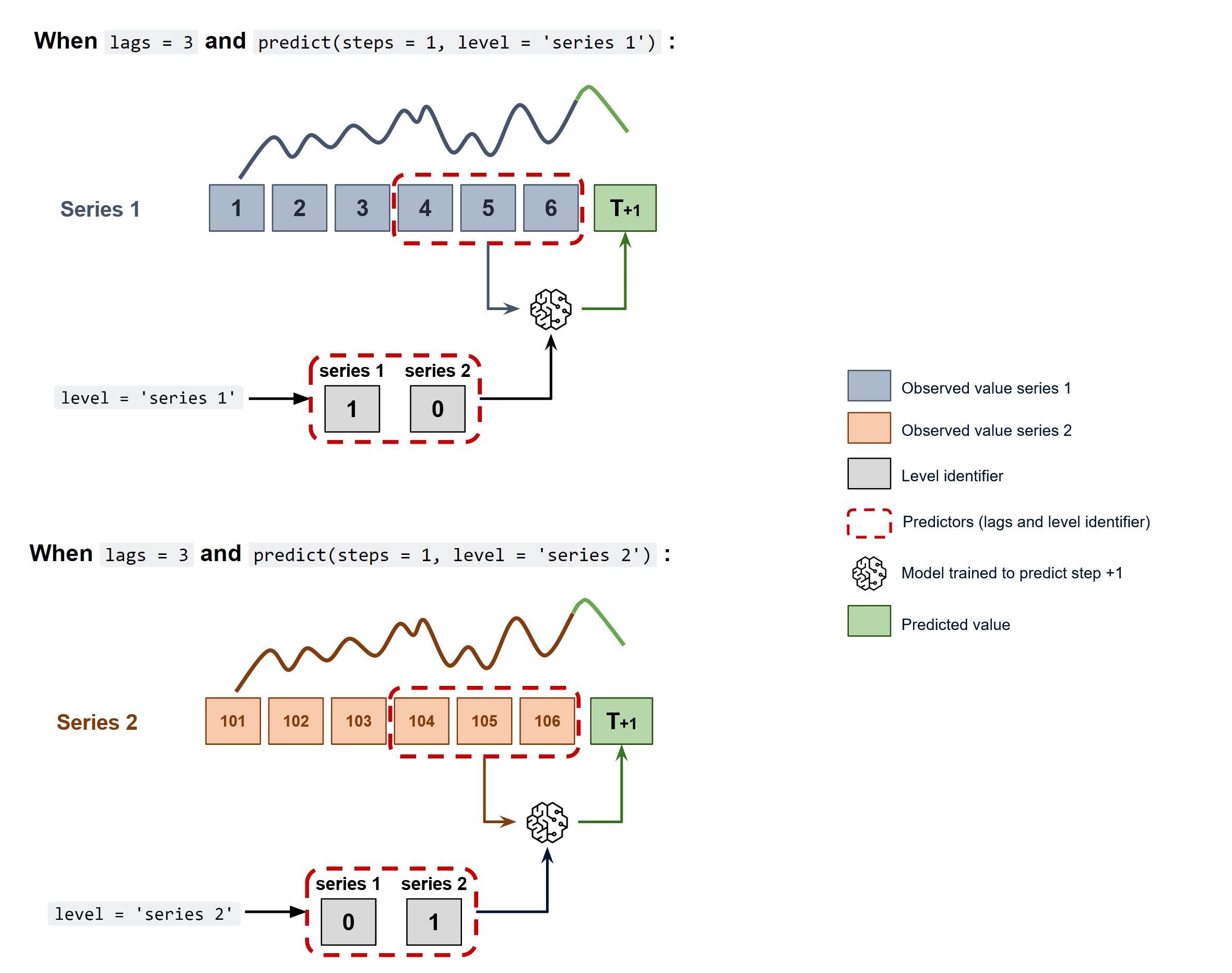
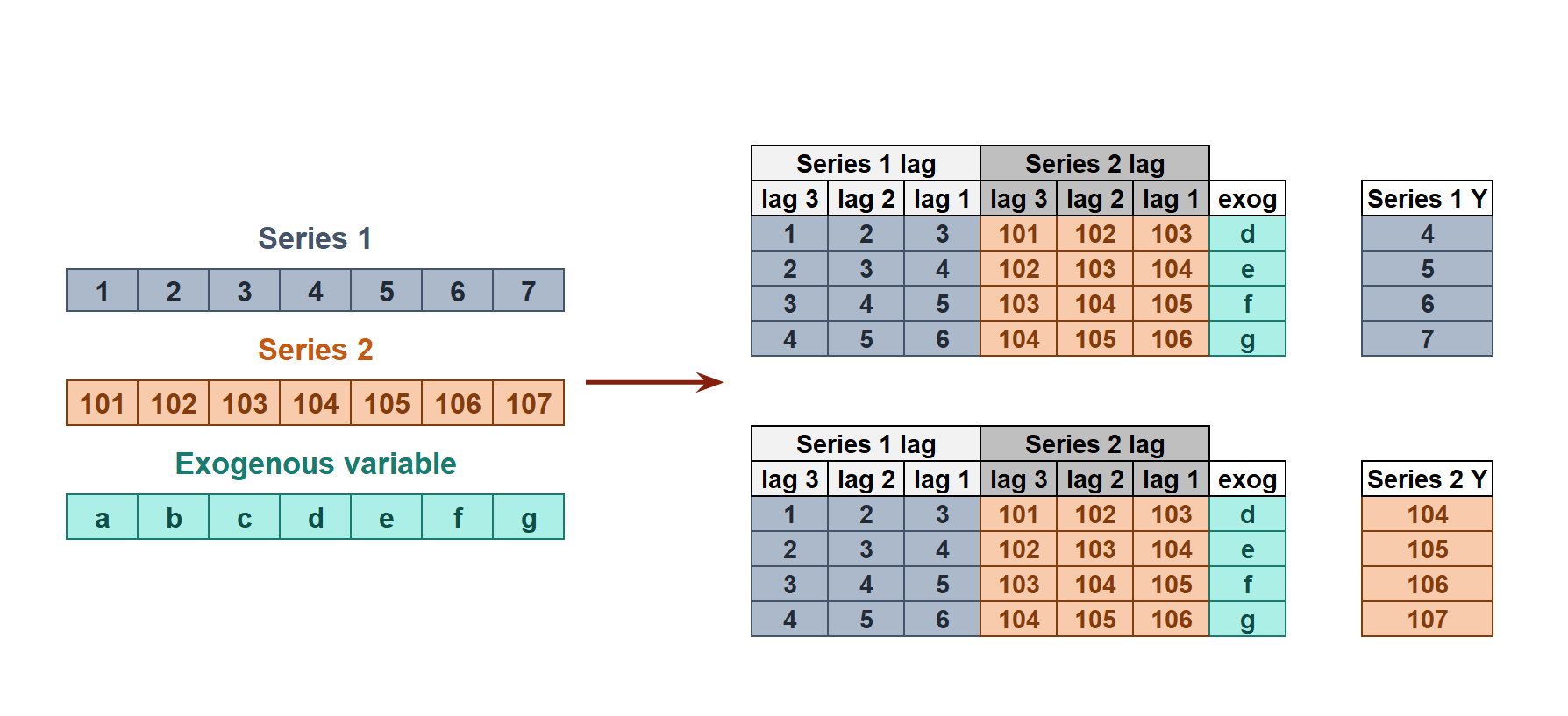
Múltiples series temporales dependientes
Todas las series se modelan teniendo en cuenta que cada serie temporal depende no sólo de sus valores pasados, sino también de los valores pasados de las demás series. Se espera que el modelo no sólo aprenda la información de cada serie por separado, sino que también las relacione. Por ejemplo, las mediciones realizadas por todos los sensores (caudal, temperatura, presión...) instalados en una máquina industrial como un compresor. Series temporales multivariantes user guide.
💡 Tip
Este es el primero de una serie de documentos sobre modelos de forecasting globales:
- Modelos de forecasting globales: modelado de múltiples series temporales con machine learning
- Forecasting escalable: modelado de mil de series temporales con un único modelo global
- Modelos de forecasting globales: Análisis comparativo de modelos de una y múltiples series
- Modelos de forecasting globales: Guía paso a paso con Kaggle Sticker Sales
Series con la misma longitud¶
En este primer ejemplo, se utilizan múltiples series temporales de la misma longitud. El objetivo es comparar los resultados de un modelo global con los de un modelo individual para cada serie al predecir los próximos 7 días de ventas para 50 productos diferentes en una tienda, utilizando los 5 años de historial disponible. Los datos se han obtenido del Store Item Demand Forecasting Challenge. Este conjunto de datos contiene 913,000 transacciones de ventas desde el 01/01/2013 hasta el 31/12/2017 para 50 productos (SKU) en 10 tiendas.
Librerías¶
# Manipulación de datos
# ==============================================================================
import numpy as np
import pandas as pd
# Gráficos
# ==============================================================================
import matplotlib.pyplot as plt
from skforecast.plot import set_dark_theme
from tqdm.notebook import tqdm
# Modelado y Forecasting
# ==============================================================================
import sklearn
import skforecast
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.preprocessing import StandardScaler
from skforecast.recursive import ForecasterRecursive, ForecasterRecursiveMultiSeries
from skforecast.model_selection import (
TimeSeriesFold,
OneStepAheadFold,
backtesting_forecaster,
bayesian_search_forecaster,
backtesting_forecaster_multiseries,
bayesian_search_forecaster_multiseries
)
from skforecast.preprocessing import (
RollingFeatures,
reshape_series_long_to_dict,
reshape_exog_long_to_dict
)
from skforecast.exceptions import OneStepAheadValidationWarning
# Warnings
# ==============================================================================
import warnings
warnings.filterwarnings('once')
color = '\033[1m\033[38;5;208m'
print(f"{color}Versión skforecast: {skforecast.__version__}")
print(f"{color}Versión scikit-learn: {sklearn.__version__}")
print(f"{color}Versión pandas: {pd.__version__}")
print(f"{color}Versión numpy: {np.__version__}")
Versión skforecast: 0.22.0 Versión scikit-learn: 1.7.2 Versión pandas: 2.3.3 Versión numpy: 2.1.3
Datos¶
# Lectura de datos
# ======================================================================================
data = pd.read_csv('./train_stores_kaggle.csv')
display(data)
print(f"Shape: {data.shape}")
| date | store | item | sales | |
|---|---|---|---|---|
| 0 | 2013-01-01 | 1 | 1 | 13 |
| 1 | 2013-01-02 | 1 | 1 | 11 |
| 2 | 2013-01-03 | 1 | 1 | 14 |
| 3 | 2013-01-04 | 1 | 1 | 13 |
| 4 | 2013-01-05 | 1 | 1 | 10 |
| ... | ... | ... | ... | ... |
| 912995 | 2017-12-27 | 10 | 50 | 63 |
| 912996 | 2017-12-28 | 10 | 50 | 59 |
| 912997 | 2017-12-29 | 10 | 50 | 74 |
| 912998 | 2017-12-30 | 10 | 50 | 62 |
| 912999 | 2017-12-31 | 10 | 50 | 82 |
913000 rows × 4 columns
Shape: (913000, 4)
# Preparación datos
# ======================================================================================
selected_store = 2 # Seleccionar una tienda
selected_items = data.item.unique()
data = data[(data['store'] == selected_store) & (data['item'].isin(selected_items))].copy()
data['date'] = pd.to_datetime(data['date'], format='%Y-%m-%d')
data = pd.pivot_table(
data = data,
values = 'sales',
index = 'date',
columns = 'item'
)
data.columns.name = None
data.columns = [f"item_{col}" for col in data.columns]
data = data.asfreq('1D')
data = data.sort_index()
data.head(4)
| item_1 | item_2 | item_3 | item_4 | item_5 | item_6 | item_7 | item_8 | item_9 | item_10 | ... | item_41 | item_42 | item_43 | item_44 | item_45 | item_46 | item_47 | item_48 | item_49 | item_50 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||||||||||
| 2013-01-01 | 12.0 | 41.0 | 19.0 | 21.0 | 4.0 | 34.0 | 39.0 | 49.0 | 28.0 | 51.0 | ... | 11.0 | 25.0 | 36.0 | 12.0 | 45.0 | 43.0 | 12.0 | 45.0 | 29.0 | 43.0 |
| 2013-01-02 | 16.0 | 33.0 | 32.0 | 14.0 | 6.0 | 40.0 | 47.0 | 42.0 | 21.0 | 56.0 | ... | 19.0 | 21.0 | 35.0 | 25.0 | 50.0 | 52.0 | 13.0 | 37.0 | 25.0 | 57.0 |
| 2013-01-03 | 16.0 | 46.0 | 26.0 | 12.0 | 12.0 | 41.0 | 43.0 | 46.0 | 29.0 | 46.0 | ... | 23.0 | 20.0 | 52.0 | 18.0 | 56.0 | 30.0 | 5.0 | 45.0 | 30.0 | 45.0 |
| 2013-01-04 | 20.0 | 50.0 | 34.0 | 17.0 | 16.0 | 41.0 | 44.0 | 55.0 | 32.0 | 56.0 | ... | 15.0 | 28.0 | 50.0 | 24.0 | 57.0 | 46.0 | 19.0 | 32.0 | 20.0 | 45.0 |
4 rows × 50 columns
El dataset se divide en 3 particiones: una para el entrenamiento, otra para la validación y otra para test.
# Separación datos train-validation-test
# ======================================================================================
end_train = '2016-05-31 23:59:00'
end_val = '2017-05-31 23:59:00'
data_train = data.loc[:end_train, :].copy()
data_val = data.loc[end_train:end_val, :].copy()
data_test = data.loc[end_val:, :].copy()
print(f"Fechas train : {data_train.index.min()} --- {data_train.index.max()} (n={len(data_train)})")
print(f"Fechas validación : {data_val.index.min()} --- {data_val.index.max()} (n={len(data_val)})")
print(f"Fechas test : {data_test.index.min()} --- {data_test.index.max()} (n={len(data_test)})")
Fechas train : 2013-01-01 00:00:00 --- 2016-05-31 00:00:00 (n=1247) Fechas validación : 2016-06-01 00:00:00 --- 2017-05-31 00:00:00 (n=365) Fechas test : 2017-06-01 00:00:00 --- 2017-12-31 00:00:00 (n=214)
Se representan cuatro de las series para comprender sus tendencias y patrones. Se recomienda al lector que grafique más de ellas para comprenderlas en profundidad.
# Gráfico series temporales
# ======================================================================================
set_dark_theme()
fig, axs = plt.subplots(4, 1, figsize=(7, 5), sharex=True)
data.iloc[:, :4].plot(
legend = True,
subplots = True,
title = 'Ventas de la tienda 2',
ax = axs,
linewidth = 1
)
for ax in axs:
ax.axvline(pd.to_datetime(end_train) , color='white', linestyle='--', linewidth=1.5)
ax.axvline(pd.to_datetime(end_val) , color='white', linestyle='--', linewidth=1.5)
fig.tight_layout();

Forecasting individual para cada item¶
Se entrena un modelo Gradient Boosting Machine (GBM) para cada producto, utilizando las ventas de los últimos 14 días, así como las ventas promedio, máxima y mínima de los últimos 7 días como predictores. El rendimiento del modelo para los siguientes 7 días se evalúa mediante backtesting utilizando el Error Absoluto Medio (MAE) como métrica de evaluación. Finalmente, se compara el rendimiento de estos modelos individuales con el de un modelo global entrenado con todas las series.
# Entrenar y realizar backtesting de un modelo para cada item
# ======================================================================================
items = []
mae_values = []
predictions = {}
for i, item in enumerate(tqdm(data.columns)):
# Definir el forecaster
window_features = RollingFeatures(stats=['mean', 'min', 'max'], window_sizes=7)
forecaster = ForecasterRecursive(
estimator = HistGradientBoostingRegressor(random_state=8523),
lags = 14,
window_features = window_features
)
# Backtesting forecaster
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(data_train) + len(data_val),
refit = False,
)
metric, preds = backtesting_forecaster(
forecaster = forecaster,
y = data[item],
cv = cv,
metric = 'mean_absolute_error',
show_progress = False
)
items.append(item)
mae_values.append(metric.at[0, 'mean_absolute_error'])
predictions[item] = preds
# Resultados
uni_series_mae = pd.Series(
data = mae_values,
index = items,
name = 'uni_series_mae'
)
uni_series_mae.head()
item_1 6.004406 item_2 9.994352 item_3 8.652751 item_4 5.528955 item_5 5.096925 Name: uni_series_mae, dtype: float64
Modelo global¶
Se entrena modelo global con las mismas características que los modelos individuales. Se evalúa el rendimiento del modelo global en el conjunto de test y se compara con el rendimiento de los modelos individuales.
# Entrenamiento y backtesting con un único modelo para todos los items
# ======================================================================================
items = list(data.columns)
# Definir el forecaster
window_features = RollingFeatures(stats=['mean', 'min', 'max'], window_sizes=7)
forecaster_ms = ForecasterRecursiveMultiSeries(
estimator = HistGradientBoostingRegressor(random_state=8523),
lags = 14,
encoding = 'ordinal',
transformer_series = StandardScaler(),
window_features = window_features,
)
# Backtesting forecaster para todos los items
cv = TimeSeriesFold(
steps = 7,
initial_train_size = len(data_train) + len(data_val),
refit = False,
)
multi_series_mae, predictions_ms = backtesting_forecaster_multiseries(
forecaster = forecaster_ms,
series = data,
levels = items,
cv = cv,
metric = 'mean_absolute_error',
)
# Resultados
display(multi_series_mae.head(3))
print('')
display(predictions_ms.head(3))
╭────────────────────────────────── InputTypeWarning ──────────────────────────────────╮ │ Passing a DataFrame (either wide or long format) as `series` requires additional │ │ internal transformations, which can increase computational time. It is recommended │ │ to use a dictionary of pandas Series instead. For more details, see: │ │ https://skforecast.org/latest/user_guides/independent-multi-time-series-forecasting. │ │ html#input-data │ │ │ │ Category : skforecast.exceptions.InputTypeWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/utils/utils.py:2802 │ │ Suppress : warnings.simplefilter('ignore', category=InputTypeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
| levels | mean_absolute_error | |
|---|---|---|
| 0 | item_1 | 5.521236 |
| 1 | item_2 | 9.245126 |
| 2 | item_3 | 7.301948 |
| level | fold | pred | |
|---|---|---|---|
| 2017-06-01 | item_1 | 0 | 35.106861 |
| 2017-06-01 | item_2 | 0 | 90.367217 |
| 2017-06-01 | item_3 | 0 | 60.613740 |
Comparación¶
# Diferencia de la métrica de backtesting para cada item
# ======================================================================================
multi_series_mae = multi_series_mae.set_index('levels')
multi_series_mae.columns = ['multi_series_mae']
results = pd.concat((uni_series_mae, multi_series_mae), axis = 1)
results['improvement'] = results.eval('uni_series_mae - multi_series_mae')
results['improvement_(%)'] = 100 * results.eval('(uni_series_mae - multi_series_mae) / uni_series_mae')
results = results.round(2)
results.style.bar(subset=['improvement_(%)'], align='mid', color=['#d65f5f', '#5fba7d'])
| uni_series_mae | multi_series_mae | improvement | improvement_(%) | |
|---|---|---|---|---|
| item_1 | 6.000000 | 5.520000 | 0.480000 | 8.050000 |
| item_2 | 9.990000 | 9.250000 | 0.750000 | 7.500000 |
| item_3 | 8.650000 | 7.300000 | 1.350000 | 15.610000 |
| item_4 | 5.530000 | 5.030000 | 0.500000 | 8.960000 |
| item_5 | 5.100000 | 4.660000 | 0.440000 | 8.630000 |
| item_6 | 10.830000 | 9.750000 | 1.080000 | 9.960000 |
| item_7 | 10.580000 | 9.830000 | 0.750000 | 7.120000 |
| item_8 | 11.810000 | 10.420000 | 1.400000 | 11.830000 |
| item_9 | 9.420000 | 8.690000 | 0.730000 | 7.760000 |
| item_10 | 11.640000 | 10.330000 | 1.300000 | 11.210000 |
| item_11 | 11.520000 | 10.430000 | 1.090000 | 9.450000 |
| item_12 | 11.960000 | 10.890000 | 1.080000 | 8.990000 |
| item_13 | 12.130000 | 11.360000 | 0.760000 | 6.300000 |
| item_14 | 10.350000 | 9.560000 | 0.790000 | 7.610000 |
| item_15 | 12.460000 | 11.640000 | 0.820000 | 6.620000 |
| item_16 | 6.000000 | 5.920000 | 0.090000 | 1.480000 |
| item_17 | 7.460000 | 7.190000 | 0.270000 | 3.560000 |
| item_18 | 12.690000 | 12.120000 | 0.570000 | 4.490000 |
| item_19 | 7.720000 | 7.370000 | 0.360000 | 4.600000 |
| item_20 | 8.250000 | 7.830000 | 0.420000 | 5.080000 |
| item_21 | 8.580000 | 8.060000 | 0.520000 | 6.080000 |
| item_22 | 11.790000 | 10.710000 | 1.080000 | 9.150000 |
| item_23 | 7.490000 | 6.770000 | 0.720000 | 9.600000 |
| item_24 | 10.470000 | 9.860000 | 0.610000 | 5.850000 |
| item_25 | 12.950000 | 11.650000 | 1.310000 | 10.100000 |
| item_26 | 9.230000 | 8.590000 | 0.640000 | 6.930000 |
| item_27 | 5.480000 | 5.170000 | 0.310000 | 5.680000 |
| item_28 | 12.590000 | 12.080000 | 0.510000 | 4.020000 |
| item_29 | 10.980000 | 10.180000 | 0.810000 | 7.330000 |
| item_30 | 8.430000 | 7.890000 | 0.530000 | 6.290000 |
| item_31 | 10.530000 | 10.070000 | 0.460000 | 4.420000 |
| item_32 | 9.710000 | 9.160000 | 0.540000 | 5.580000 |
| item_33 | 9.740000 | 9.320000 | 0.420000 | 4.270000 |
| item_34 | 6.340000 | 5.930000 | 0.410000 | 6.450000 |
| item_35 | 11.200000 | 10.180000 | 1.020000 | 9.120000 |
| item_36 | 12.000000 | 10.620000 | 1.380000 | 11.520000 |
| item_37 | 6.510000 | 6.110000 | 0.400000 | 6.150000 |
| item_38 | 11.620000 | 11.130000 | 0.500000 | 4.270000 |
| item_39 | 8.340000 | 7.370000 | 0.970000 | 11.680000 |
| item_40 | 7.100000 | 6.630000 | 0.470000 | 6.650000 |
| item_41 | 5.670000 | 5.220000 | 0.450000 | 7.950000 |
| item_42 | 7.440000 | 6.940000 | 0.500000 | 6.680000 |
| item_43 | 8.620000 | 8.570000 | 0.050000 | 0.540000 |
| item_44 | 6.980000 | 6.410000 | 0.570000 | 8.190000 |
| item_45 | 12.720000 | 11.790000 | 0.930000 | 7.310000 |
| item_46 | 10.350000 | 9.890000 | 0.460000 | 4.450000 |
| item_47 | 5.500000 | 4.980000 | 0.520000 | 9.500000 |
| item_48 | 9.270000 | 8.190000 | 1.090000 | 11.740000 |
| item_49 | 6.300000 | 5.960000 | 0.340000 | 5.350000 |
| item_50 | 11.860000 | 10.610000 | 1.250000 | 10.510000 |
| average | nan | 8.620000 | nan | nan |
| weighted_average | nan | 8.620000 | nan | nan |
| pooling | nan | 8.620000 | nan | nan |
# Mejora media de todos los items
# ======================================================================================
results[['improvement', 'improvement_(%)']].agg(['mean', 'min', 'max'])
| improvement | improvement_(%) | |
|---|---|---|
| mean | 0.696 | 7.3634 |
| min | 0.050 | 0.5400 |
| max | 1.400 | 15.6100 |
# Número de series con mejora positiva y negativa
# ======================================================================================
pd.Series(np.where(results['improvement_(%)'] < 0, 'negative', 'positive')).value_counts()
positive 53 Name: count, dtype: int64
El modelo global logra una mejora media del 7.4% en comparación con el uso de un modelo individual para cada serie. Para todas las series, el error de predicción evaluado mediante backtesting es menor cuando se utiliza el modelo global. Este caso de uso demuestra que un modelo multiserie puede tener ventajas sobre varios modelos individuales a la hora de predecir series temporales que siguen una dinámica similar. Además de las mejoras potenciales en la predicción, también es importante tener en cuenta el beneficio de tener un único modelo que mantener y la velocidad de entrenamiento y predicción.
⚠️ Warning
Esta comparación se ha realizado sin optimizar los hiperparámetros del modelo. Consulte la sección Ajuste de hiperparámetros y selección de lags para comprobar que las conclusiones se mantienen cuando los modelos se ajustan con la mejor combinación de hiperparámetros y lags.
Series de diferente longitud y distintas variables exógenas¶
En escenarios en los que se tienen que modelar múltiples series, es habitual que las series tengan longitudes distintas debido a diferencias en los momentos de inicio del registro de los datos. Para hacer frente a este escenario, la clase ForecasterRecursiveMultiSeries permite modelizar simultáneamente series temporales de distintas longitudes y con distintas variables exógenas. En estos casos, los datos deben estructurarse en una de las siguientes formas:
En un
diccionariodepandas.Series: las claves del diccionario son los nombres de las series y los valores son las propias series. Todas las series deben ser del tipopandas.Series, tener un índiceDatetimeIndexy la misma frecuencia.En un
pandas.DataFrameconMultiIndex: el que el primer nivel del índice debe contener el nombre de la serie y el segundo nivel es el índice temporal. Todas las series deben ser del tipopandas.Series, tener un índiceDatetimeIndexy tener la misma frecuencia. Esta opción está disponible a partir de la versión0.17.0de skforecast.
| Series values | Permitido |
|---|---|
[NaN, NaN, NaN, NaN, 4, 5, 6, 7, 8, 9] |
✔️ |
[0, 1, 2, 3, 4, 5, 6, 7, 8, NaN] |
✔️ |
[0, 1, 2, 3, 4, NaN, 6, 7, 8, 9] |
✔️ |
[NaN, NaN, 2, 3, 4, NaN, 6, 7, 8, 9] |
✔️ |
Cuando se utilizan variables exógenas diferentes para cada serie o cuando las variables exógenas son las mismas pero tienen valores diferentes para cada serie, deben utilizarse alguna de las siguientes opciones:
En un diccionario: Las claves del diccionario son los nombres de las series y los valores son las propias variables exógenas. Todas las variables exógenas deben ser de tipo
pandas.DataFrameopandas.Series.En un
pandas.DataFrameconMultiIndex: el primer nivel del índice debe contener el nombre de la serie y el segundo nivel es el índice temporal. Todas las variables exógenas deben ser del tipopandas.DataFrameopandas.Series.
Si los datos no siguen estas estructuras, skforecast proporciona dos funciones para transformar los datos: reshape_series_long_to_dict y reshape_exog_long_to_dict.
💡 Tip
En términos de rendimiento, el uso de un diccionario es más eficiente que un DataFrame de pandas, ya sea en formato ancho o largo, especialmente para conjuntos de datos más grandes. Esto se debe a que los diccionarios permiten un acceso y manipulación más rápidos de series temporales individuales, sin la sobrecarga estructural asociada a los DataFrames.
Datos¶
Los datos de este ejemplo están almacenados en "formato largo" en un único DataFrame. La columna series_id identifica la serie a la que pertenece cada observación. La columna timestamp contiene la fecha de la observación, y la columna value contiene el valor de la serie en esa fecha. Cada serie temporal tiene una longitud diferente.
Las variables exógenas se almacenan en un DataFrame separado, también en "formato largo". La columna series_id identifica la serie a la que pertenece cada observación. La columna timestamp contiene la fecha de la observación, y las columnas restantes contienen los valores de las variables exógenas en esa fecha.
# Lectura series con diferentes longitudes y variables exógenas
# ==============================================================================
series = pd.read_csv(
'https://raw.githubusercontent.com/skforecast/skforecast-datasets/main/data/demo_multi_series.csv'
)
exog = pd.read_csv(
'https://raw.githubusercontent.com/skforecast/skforecast-datasets/main/data/demo_multi_series_exog.csv'
)
series['timestamp'] = pd.to_datetime(series['timestamp'])
exog['timestamp'] = pd.to_datetime(exog['timestamp'])
display(series.head())
display(exog.head())
| series_id | timestamp | value | |
|---|---|---|---|
| 0 | id_1000 | 2016-01-01 | 1012.500694 |
| 1 | id_1000 | 2016-01-02 | 1158.500099 |
| 2 | id_1000 | 2016-01-03 | 983.000099 |
| 3 | id_1000 | 2016-01-04 | 1675.750496 |
| 4 | id_1000 | 2016-01-05 | 1586.250694 |
| series_id | timestamp | sin_day_of_week | cos_day_of_week | air_temperature | wind_speed | |
|---|---|---|---|---|---|---|
| 0 | id_1000 | 2016-01-01 | -0.433884 | -0.900969 | 6.416639 | 4.040115 |
| 1 | id_1000 | 2016-01-02 | -0.974928 | -0.222521 | 6.366474 | 4.530395 |
| 2 | id_1000 | 2016-01-03 | -0.781831 | 0.623490 | 6.555272 | 3.273064 |
| 3 | id_1000 | 2016-01-04 | 0.000000 | 1.000000 | 6.704778 | 4.865404 |
| 4 | id_1000 | 2016-01-05 | 0.781831 | 0.623490 | 2.392998 | 5.228913 |
Cuando las series tienen longitudes diferentes, los datos deben transformarse en un diccionario. Las claves del diccionario son los nombres de las series y los valores son las propias series. Para ello, se utiliza la función reshape_series_long_to_dict, que toma el DataFrame en "formato largo" y devuelve un diccionario de series.
Del mismo modo, cuando las variables exógenas son diferentes (valores o variables) para cada serie, los datos deben transformarse en un diccionario. Las claves del diccionario son los nombres de las series y los valores son las propias variables exógenas. Se utiliza la función reshape_exog_long_to_dict, que toma el DataFrame en "formato largo" y devuelve un diccionario de variables exógenas.
# Transform series and exog to dictionaries
# ==============================================================================
series_dict = reshape_series_long_to_dict(
data = series,
series_id = 'series_id',
index = 'timestamp',
values = 'value',
freq = 'D'
)
exog_dict = reshape_exog_long_to_dict(
data = exog,
series_id = 'series_id',
index = 'timestamp',
freq = 'D'
)
╭──────────────────────────────── MissingValuesWarning ────────────────────────────────╮ │ Series 'id_1003' is incomplete. NaNs have been introduced after setting the │ │ frequency. │ │ │ │ Category : skforecast.exceptions.MissingValuesWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/preprocessing/preprocessing.py:534 │ │ Suppress : warnings.simplefilter('ignore', category=MissingValuesWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
Algunas variables exógenas se omiten en las series 1 y 3 para ilustrar que se pueden utilizar diferentes variables exógenas para cada serie.
exog_dict['id_1000'] = exog_dict['id_1000'].drop(columns=['air_temperature', 'wind_speed'])
exog_dict['id_1003'] = exog_dict['id_1003'].drop(columns=['cos_day_of_week'])
# Particiones de entrenamiento y test
# ==============================================================================
end_train = '2016-07-31 23:59:00'
series_dict_train = {k: v.loc[: end_train,] for k, v in series_dict.items()}
exog_dict_train = {k: v.loc[: end_train,] for k, v in exog_dict.items()}
series_dict_test = {k: v.loc[end_train:,] for k, v in series_dict.items()}
exog_dict_test = {k: v.loc[end_train:,] for k, v in exog_dict.items()}
# Gráfico series
# ==============================================================================
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
fig, axs = plt.subplots(5, 1, figsize=(8, 4), sharex=True)
for i, s in enumerate(series_dict.values()):
axs[i].plot(s, label=s.name, color=colors[i])
axs[i].legend(loc='upper right', fontsize=8)
axs[i].tick_params(axis='both', labelsize=8)
axs[i].axvline(pd.to_datetime(end_train), color='white', linestyle='--', linewidth=1)

# Descripción de cada serie
# ==============================================================================
for k in series_dict.keys():
print(f"{k}:")
try:
print(
f"\tTrain: len={len(series_dict_train[k])}, {series_dict_train[k].index[0]}"
f" --- {series_dict_train[k].index[-1]} "
f" (missing={series_dict_train[k].isnull().sum()})"
)
except:
print(f"\tTrain: len=0")
try:
print(
f"\tTest : len={len(series_dict_test[k])}, {series_dict_test[k].index[0]}"
f" --- {series_dict_test[k].index[-1]} "
f" (missing={series_dict_test[k].isnull().sum()})"
)
except:
print(f"\tTest : len=0")
id_1000: Train: len=213, 2016-01-01 00:00:00 --- 2016-07-31 00:00:00 (missing=0) Test : len=153, 2016-08-01 00:00:00 --- 2016-12-31 00:00:00 (missing=0) id_1001: Train: len=30, 2016-07-02 00:00:00 --- 2016-07-31 00:00:00 (missing=0) Test : len=153, 2016-08-01 00:00:00 --- 2016-12-31 00:00:00 (missing=0) id_1002: Train: len=183, 2016-01-01 00:00:00 --- 2016-07-01 00:00:00 (missing=0) Test : len=0 id_1003: Train: len=213, 2016-01-01 00:00:00 --- 2016-07-31 00:00:00 (missing=73) Test : len=153, 2016-08-01 00:00:00 --- 2016-12-31 00:00:00 (missing=73) id_1004: Train: len=91, 2016-05-02 00:00:00 --- 2016-07-31 00:00:00 (missing=0) Test : len=31, 2016-08-01 00:00:00 --- 2016-08-31 00:00:00 (missing=0)
# Variables exógenas de cada serie
# ==============================================================================
for k in series_dict.keys():
print(f"{k}:")
try:
print(f"\t{exog_dict[k].columns.to_list()}")
except:
print(f"\tNo variables exógenas")
id_1000: ['sin_day_of_week', 'cos_day_of_week'] id_1001: ['sin_day_of_week', 'cos_day_of_week', 'air_temperature', 'wind_speed'] id_1002: ['sin_day_of_week', 'cos_day_of_week', 'air_temperature', 'wind_speed'] id_1003: ['sin_day_of_week', 'air_temperature', 'wind_speed'] id_1004: ['sin_day_of_week', 'cos_day_of_week', 'air_temperature', 'wind_speed']
Modelo global¶
# Fit forecaster
# ==============================================================================
estimator = HistGradientBoostingRegressor(random_state=123, max_depth=5)
window_features = RollingFeatures(stats=['mean', 'min', 'max'], window_sizes=7)
forecaster = ForecasterRecursiveMultiSeries(
estimator = estimator,
lags = 14,
window_features = window_features,
encoding = "ordinal",
dropna_from_series = False
)
forecaster.fit(series=series_dict_train, exog=exog_dict_train, suppress_warnings=True)
forecaster
ForecasterRecursiveMultiSeries
General Information
- Estimator: HistGradientBoostingRegressor
- Lags: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
- Window features: ['roll_mean_7', 'roll_min_7', 'roll_max_7']
- Window size: 14
- Series encoding: ordinal
- Exogenous included: True
- Categorical features: auto
- Weight function included: False
- Series weights: None
- Differentiation order: None
- Drop NaN from series: False
- Creation date: 2026-04-23 12:44:48
- Last fit date: 2026-04-23 12:44:48
- Skforecast version: 0.22.0
- Python version: 3.13.12
- Forecaster id: None
Exogenous Variables
sin_day_of_week, cos_day_of_week, air_temperature, wind_speed
Data Transformations
- Transformer for series: None
- Transformer for exog: None
Training Information
- Series names (levels): id_1000, id_1001, id_1002, id_1003, id_1004
- Training range: 'id_1000': ['2016-01-01', '2016-07-31'], 'id_1001': ['2016-07-02', '2016-07-31'], 'id_1002': ['2016-01-01', '2016-07-01'], 'id_1003': ['2016-01-01', '2016-07-31'], 'id_1004': ['2016-05-02', '2016-07-31']
- Training index type: DatetimeIndex
- Training index frequency:
Estimator Parameters
-
{'categorical_features': 'from_dtype', 'early_stopping': 'auto', 'interaction_cst': None, 'l2_regularization': 0.0, 'learning_rate': 0.1, 'loss': 'squared_error', 'max_bins': 255, 'max_depth': 5, 'max_features': 1.0, 'max_iter': 100, 'max_leaf_nodes': 31, 'min_samples_leaf': 20, 'monotonic_cst': None, 'n_iter_no_change': 10, 'quantile': None, 'random_state': 123, 'scoring': 'loss', 'tol': 1e-07, 'validation_fraction': 0.1, 'verbose': 0, 'warm_start': False}
Fit Kwargs
-
{}
Sólo se pueden predecir juntas las series cuya última ventana de datos (last_window) termine en el mismo índice fecha-hora. Si levels = None, se excluyen de la predicción las series que no alcanzan el índice máximo. En este ejemplo, la serie 'id_1002 se excluye.
# Predict
# ==============================================================================
predicciones = forecaster.predict(steps=5, exog=exog_dict_test, suppress_warnings=True)
predicciones
| level | pred | |
|---|---|---|
| 2016-08-01 | id_1000 | 1433.494674 |
| 2016-08-01 | id_1001 | 3068.244797 |
| 2016-08-01 | id_1003 | 2748.768695 |
| 2016-08-01 | id_1004 | 7763.964965 |
| 2016-08-02 | id_1000 | 1465.937652 |
| 2016-08-02 | id_1001 | 3468.972018 |
| 2016-08-02 | id_1003 | 2022.956989 |
| 2016-08-02 | id_1004 | 8734.459604 |
| 2016-08-03 | id_1000 | 1407.568704 |
| 2016-08-03 | id_1001 | 3475.785941 |
| 2016-08-03 | id_1003 | 1860.174602 |
| 2016-08-03 | id_1004 | 9111.776904 |
| 2016-08-04 | id_1000 | 1355.034624 |
| 2016-08-04 | id_1001 | 3356.315154 |
| 2016-08-04 | id_1003 | 1823.007406 |
| 2016-08-04 | id_1004 | 8815.493044 |
| 2016-08-05 | id_1000 | 1298.820257 |
| 2016-08-05 | id_1001 | 3325.735999 |
| 2016-08-05 | id_1003 | 1815.224166 |
| 2016-08-05 | id_1004 | 8664.891475 |
Backtesting¶
Cuando las series tienen longitudes diferentes, el proceso de backtesting sólo devuelve predicciones para las fechas-horas que están presentes en las series.
# Backtesting
# ==============================================================================
cv = TimeSeriesFold(
steps = 24,
initial_train_size = len(series_dict_train["id_1000"]),
refit = False,
)
metrics_levels, backtest_predictions = backtesting_forecaster_multiseries(
forecaster = forecaster,
series = series_dict,
exog = exog_dict,
cv = cv,
metric = "mean_absolute_error",
add_aggregated_metric = False,
verbose = True,
suppress_warnings = True
)
display(metrics_levels)
display(backtest_predictions)
Information of folds
--------------------
Number of observations used for initial training: 213
Number of observations used for backtesting: 153
Number of folds: 7
Number skipped folds: 0
Number of steps per fold: 24
Number of steps to exclude between last observed data (last window) and predictions (gap): 0
Last fold only includes 9 observations.
Fold: 0
Training: 2016-01-01 00:00:00 -- 2016-07-31 00:00:00 (n=213)
Validation: 2016-08-01 00:00:00 -- 2016-08-24 00:00:00 (n=24)
Fold: 1
Training: No training in this fold
Validation: 2016-08-25 00:00:00 -- 2016-09-17 00:00:00 (n=24)
Fold: 2
Training: No training in this fold
Validation: 2016-09-18 00:00:00 -- 2016-10-11 00:00:00 (n=24)
Fold: 3
Training: No training in this fold
Validation: 2016-10-12 00:00:00 -- 2016-11-04 00:00:00 (n=24)
Fold: 4
Training: No training in this fold
Validation: 2016-11-05 00:00:00 -- 2016-11-28 00:00:00 (n=24)
Fold: 5
Training: No training in this fold
Validation: 2016-11-29 00:00:00 -- 2016-12-22 00:00:00 (n=24)
Fold: 6
Training: No training in this fold
Validation: 2016-12-23 00:00:00 -- 2016-12-31 00:00:00 (n=9)
| levels | mean_absolute_error | |
|---|---|---|
| 0 | id_1000 | 164.959423 |
| 1 | id_1001 | 1055.559754 |
| 2 | id_1002 | NaN |
| 3 | id_1003 | 235.663130 |
| 4 | id_1004 | 968.459237 |
| level | fold | pred | |
|---|---|---|---|
| 2016-08-01 | id_1000 | 0 | 1433.494674 |
| 2016-08-01 | id_1001 | 0 | 3068.244797 |
| 2016-08-01 | id_1003 | 0 | 2748.768695 |
| 2016-08-01 | id_1004 | 0 | 7763.964965 |
| 2016-08-02 | id_1000 | 0 | 1465.937652 |
| ... | ... | ... | ... |
| 2016-12-30 | id_1001 | 6 | 1114.592910 |
| 2016-12-30 | id_1003 | 6 | 1965.060657 |
| 2016-12-31 | id_1000 | 6 | 1459.122750 |
| 2016-12-31 | id_1001 | 6 | 1001.655092 |
| 2016-12-31 | id_1003 | 6 | 1969.768680 |
507 rows × 3 columns
# Gráfico predicciones backtesting
# ==============================================================================
colors = plt.rcParams["axes.prop_cycle"].by_key()["color"]
fig, axs = plt.subplots(5, 1, figsize=(8, 4), sharex=True)
for i, s in enumerate(series_dict.keys()):
axs[i].plot(series_dict[s], label=series_dict[s].name, color=colors[i])
axs[i].axvline(pd.to_datetime(end_train), color="white", linestyle="--", linewidth=1)
try:
axs[i].plot(
backtest_predictions.loc[backtest_predictions["level"] == s, "pred"],
label="prediction",
color="white",
)
except:
pass
axs[i].legend(loc="upper left", fontsize=8)
axs[i].tick_params(axis="both", labelsize=8)

Al permitir la modelización de series temporales de diferentes longitudes y con diferentes variables exógenas, la clase ForecasterRecursiveMultiSeries proporciona una herramienta flexible y potente para utilizar toda la información disponible para entrenar los modelos.
Optimización de hiperparámetros y lags¶
En el primer ejemplo de este documento, la comparación entre forecaster se ha realizado sin optimizar los hiperparámetros de los regresores. Para una comparación justa, se utiliza una estrategia de grid search con el fin de seleccionar la mejor configuración para cada forecaster. Véase más información en hyperparameter tuning and lags selection.
✏️ Note
Optimizar los hiperparámetros de múltiples modelos puede ser computacionalmente costoso. Para acelerar el proceso, la evaluación de cada configuración candidata se realiza utilizando one-step-ahead en lugar de backtesting. Para más detalles sobre las ventajas y limitaciones de este enfoque, consulte One-step-ahead validation.
# Búsqueda de hiperparámetros y backtesting de un modelo para cada item
# ==============================================================================
warnings.simplefilter('ignore', category=OneStepAheadValidationWarning)
items = []
mae_values = []
def search_space(trial):
search_space = {
'lags' : trial.suggest_categorical('lags', [7, 14]),
'max_iter' : trial.suggest_int('max_iter', 100, 500),
'max_depth' : trial.suggest_int('max_depth', 5, 10),
'learning_rate' : trial.suggest_float('learning_rate', 0.01, 0.1)
}
return search_space
for item in tqdm(data.columns):
window_features = RollingFeatures(stats=['mean', 'min', 'max'], window_sizes=7)
forecaster = ForecasterRecursive(
estimator = HistGradientBoostingRegressor(random_state=123),
lags = 14,
window_features = window_features
)
cv_search = OneStepAheadFold(initial_train_size = len(data_train))
warnings.simplefilter('ignore', category=OneStepAheadValidationWarning)
results_search, _ = bayesian_search_forecaster(
forecaster = forecaster,
y = data.loc[:end_val, item],
cv = cv_search,
search_space = search_space,
n_trials = 10,
metric = 'mean_absolute_error',
return_best = False,
show_progress = False
)
best_params = results_search.at[0, 'params']
best_lags = results_search.at[0, 'lags']
forecaster.set_params(best_params)
forecaster.set_lags(best_lags)
cv_backtesting = TimeSeriesFold(
steps = 7,
initial_train_size = len(data_train) + len(data_val),
refit = False,
)
metric, preds = backtesting_forecaster(
forecaster = forecaster,
y = data[item],
cv = cv_backtesting,
metric = 'mean_absolute_error',
show_progress = False
)
items.append(item)
mae_values.append(metric.at[0, 'mean_absolute_error'])
uni_series_mae = pd.Series(
data = mae_values,
index = items,
name = 'uni_series_mae'
)
# Busqueda de hiperparámetros y backtesting de un modelo global para todos los items
# ==============================================================================
def search_space(trial):
search_space = {
'lags' : trial.suggest_categorical('lags', [7, 14]),
'max_iter' : trial.suggest_int('max_iter', 100, 500),
'max_depth' : trial.suggest_int('max_depth', 5, 10),
'learning_rate' : trial.suggest_float('learning_rate', 0.01, 0.1)
}
return search_space
forecaster_ms = ForecasterRecursiveMultiSeries(
estimator = HistGradientBoostingRegressor(random_state=123),
lags = 14,
transformer_series = StandardScaler(),
encoding = 'ordinal'
)
results_bayesian_ms = bayesian_search_forecaster_multiseries(
forecaster = forecaster_ms,
series = data.loc[:end_val, :],
levels = None, # Si es None se seleccionan todos los niveles
cv = cv_search,
search_space = search_space,
n_trials = 20,
metric = 'mean_absolute_error',
)
multi_series_mae, predictions_ms = backtesting_forecaster_multiseries(
forecaster = forecaster_ms,
series = data,
levels = None, # Si es None se seleccionan todos los niveles
cv = cv_backtesting,
metric = 'mean_absolute_error',
add_aggregated_metric = False,
)
╭────────────────────────────────── InputTypeWarning ──────────────────────────────────╮ │ Passing a DataFrame (either wide or long format) as `series` requires additional │ │ internal transformations, which can increase computational time. It is recommended │ │ to use a dictionary of pandas Series instead. For more details, see: │ │ https://skforecast.org/latest/user_guides/independent-multi-time-series-forecasting. │ │ html#input-data │ │ │ │ Category : skforecast.exceptions.InputTypeWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/utils/utils.py:2802 │ │ Suppress : warnings.simplefilter('ignore', category=InputTypeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────── InputTypeWarning ──────────────────────────────────╮ │ Passing a DataFrame (either wide or long format) as `series` requires additional │ │ internal transformations, which can increase computational time. It is recommended │ │ to use a dictionary of pandas Series instead. For more details, see: │ │ https://skforecast.org/latest/user_guides/independent-multi-time-series-forecasting. │ │ html#input-data │ │ │ │ Category : skforecast.exceptions.InputTypeWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/utils/utils.py:2802 │ │ Suppress : warnings.simplefilter('ignore', category=InputTypeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
# Diferencia de la métrica de backtesting para cada item
# ==============================================================================
multi_series_mae = multi_series_mae.set_index('levels')
multi_series_mae.columns = ['multi_series_mae']
results = pd.concat((uni_series_mae, multi_series_mae), axis = 1)
results['improvement'] = results.eval('uni_series_mae - multi_series_mae')
results['improvement_(%)'] = 100 * results.eval('(uni_series_mae - multi_series_mae) / uni_series_mae')
results = results.round(2)
# Mejora media de todos los items
# ==============================================================================
results[['improvement', 'improvement_(%)']].agg(['mean', 'min', 'max'])
| improvement | improvement_(%) | |
|---|---|---|
| mean | 0.61 | 6.5094 |
| min | 0.04 | 0.6700 |
| max | 1.50 | 13.0900 |
# Número de series con mejora positiva y negativa
# ==============================================================================
pd.Series(np.where(results['improvement_(%)'] < 0, 'negative', 'positive')).value_counts()
positive 50 Name: count, dtype: int64
Tras identificar la combinación de lags e hiperparámetros que logran el mejor rendimiento predictivo para cada forecaster, un número superior de modelos univariantes han logrado una mayor capacidad predictiva. Aun así, el modelo multiserie proporciona mejores resultados para la mayoría de los items.
Selección de predictores¶
La selección de predictores es el proceso de seleccionar un subconjunto de predictores relevantes (variables) para su uso en la construcción del modelo. Las técnicas de selección de predictores se utilizan por varias razones: para simplificar los modelos y hacerlos más fáciles de interpretar, para reducir el tiempo de entrenamiento, para evitar los problemas de dimensionalidad, para mejorar la generalización reduciendo el sobreajuste (formalmente, la reducción de la varianza), entre otros.
Skforecast es compatible con los métodos de selección implementados en scikit-learn. Existen varios métodos de selección de características, pero los más comunes son:
Recursive feature elimination (RFE)
Sequential Feature Selection (SFS)
Feature selection based on threshold (SelectFromModel)
💡 Tip
La selección de predictores es una herramienta poderosa para mejorar el rendimiento de los modelos de machine learning. Sin embargo, es computacionalmente costosa y puede llevar tiempo. Dado que el objetivo es encontrar el mejor subconjunto de variables, no el mejor modelo, no es necesario utilizar todo el conjunto de datos o un modelo muy complejo. En su lugar, se recomienda utilizar un pequeño subconjunto de datos y un modelo simple. Una vez que se haya identificado el mejor subconjunto de variables, el modelo puede entrenarse utilizando todo el conjunto de datos y una configuración más compleja.
Pesos en forecasting multiseries¶
Los pesos se utilizan para controlar la influencia que tiene cada observación en el entrenamiento del modelo. ForecasterRecursiveMultiseries acepta dos tipos de pesos:
series_weightscontrola la importancia relativa de cada serie. Si una serie tiene el doble de peso que las demás, las observaciones de esa serie influyen el doble en el entrenamiento. Cuanto mayor sea el peso de una serie en relación con las demás, más se centrará el modelo en intentar aprender esa serie.weight_funccontrola la importancia relativa de cada observación en función del índice. Por ejemplo, una función que asigna un peso menor a ciertas fechas.
Si se indican los dos tipos de pesos, estos se multiplican para crear los pesos finales como se muestra en la figura. El sample_weight resultante no puede contener valores negativos.
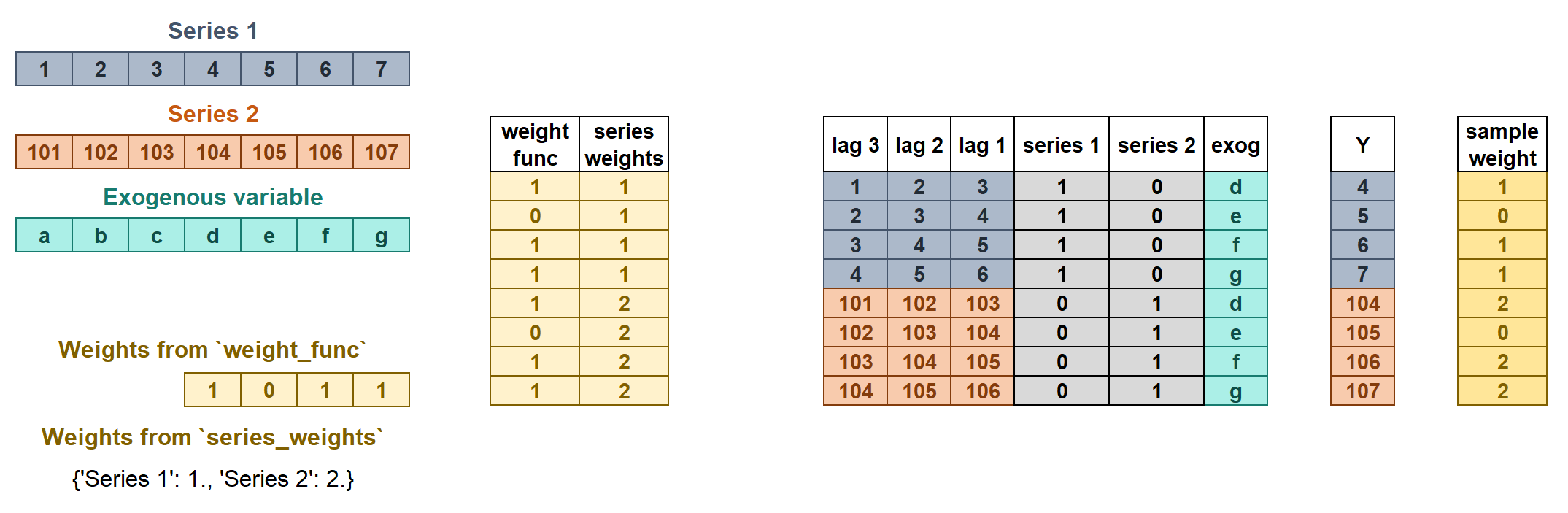
Más información sobre weights in multi-series forecasting y weighted time series forecasting con skforecast.
En este ejemplo, item_1 tiene una mayor importancia relativa entre series (pesa 3 veces más que el resto de series), y las observaciones entre '2013-12-01' y '2014-01-31' se consideran no representativas y se les aplica un peso de 0.
# Pesos en forecasting multiseries
# ======================================================================================
# Pesos de cada serie
series_weights = {'item_1': 3.0} # Las series que no aparezcan en el dict tienen un peso de 1
# Pesos de cada observación (por índice)
def custom_weights(index):
"""
Devuelve 0 si el índice está entre '2013-12-01' y '2014-01-31', 1 en caso contrario.
"""
weights = np.where(
(index >= '2013-12-01') & (index <= '2014-01-31'),
0,
1
)
return weights
forecaster = ForecasterRecursiveMultiSeries(
estimator = HistGradientBoostingRegressor(random_state=123),
lags = 14,
transformer_series = StandardScaler(),
transformer_exog = None,
weight_func = custom_weights,
series_weights = series_weights
)
forecaster.fit(series=data)
forecaster.predict(steps=7).head(3)
╭────────────────────────────────── InputTypeWarning ──────────────────────────────────╮ │ Passing a DataFrame (either wide or long format) as `series` requires additional │ │ internal transformations, which can increase computational time. It is recommended │ │ to use a dictionary of pandas Series instead. For more details, see: │ │ https://skforecast.org/latest/user_guides/independent-multi-time-series-forecasting. │ │ html#input-data │ │ │ │ Category : skforecast.exceptions.InputTypeWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/utils/utils.py:2802 │ │ Suppress : warnings.simplefilter('ignore', category=InputTypeWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭─────────────────────────────── IgnoredArgumentWarning ───────────────────────────────╮ │ {'item_6', 'item_17', 'item_18', 'item_32', 'item_45', 'item_28', 'item_13', │ │ 'item_8', 'item_25', 'item_44', 'item_4', 'item_3', 'item_16', 'item_15', 'item_23', │ │ 'item_14', 'item_12', 'item_27', 'item_29', 'item_36', 'item_20', 'item_41', │ │ 'item_24', 'item_26', 'item_42', 'item_50', 'item_31', 'item_33', 'item_10', │ │ 'item_46', 'item_19', 'item_47', 'item_48', 'item_40', 'item_30', 'item_37', │ │ 'item_2', 'item_39', 'item_22', 'item_9', 'item_43', 'item_7', 'item_49', 'item_34', │ │ 'item_38', 'item_11', 'item_21', 'item_35', 'item_5'} not present in │ │ `series_weights`. A weight of 1 is given to all their samples. │ │ │ │ Category : skforecast.exceptions.IgnoredArgumentWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/recursive/_forecaster_recursive_multiseries.py:1783 │ │ Suppress : warnings.simplefilter('ignore', category=IgnoredArgumentWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
| level | pred | |
|---|---|---|
| 2018-01-01 | item_1 | 20.583876 |
| 2018-01-01 | item_10 | 61.580282 |
| 2018-01-01 | item_11 | 62.323468 |
✏️ Note
Se puede pasar un diccionario a weight_func para aplicar diferentes funciones a cada serie. Si una serie no se presenta en el diccionario, tendrá peso
Predecir nuevas series (series desconocidas)¶
ForecasterRecursiveMultiseries permite predecir series desconocidas (series no vistas durante el proceso de entrenamiento). Pueden darse dos escenarios:
Existen datos históricos para la nueva serie: El usuario debe proporcionar un
DataFramecon los datos históricos necesarios para crear los predictores (lags y rolling) utilizados durante el proceso de predicción. EsteDataFramedebe contener una columna por cada serie que se desee predecir. Es posible incluir tanto series vistas durante el entrenamiento como series nuevas (no vistas).No existen datos históricos para la nueva serie: Este escenario es similar, pero la
last_windowpara las nuevas series está compuesta completamente por valoresNaN. Este enfoque solo es posible cuando se utilizan regresores que soportan valores faltantes, ya que todos los lags seránNaN.
En ambos casos, las variables exógenas pueden estar disponibles o no. Si no están disponibles, se establecerán automáticamente como NaN.
# Predecir nuevas series con datos históricos disponibles
# ==============================================================================
# Crear un dataframe con las últimas 14 observaciones de la nueva serie
last_window_new = pd.DataFrame(
{
"series_new_1": [1671.50059509, 1544.75089264, 1478.75059509, 1336.50069427,
1277.75039673, 1003.25049591, 820.25009918, 1075.75049591,
1409.251091 , 1344.75059509, 1310.00039673, 1297.00089264,
1103.50039673, 871.50019836],
"series_new_2": [2695.2603035 , 1980.37118912, 1929.88060379, 1817.25070572,
1784.12020111, 1986.88029099, 2257.11999512, 2489.26069641,
1994.50059509, 1830.8717804 , 1776.25099182, 1644.001091,
1943.50058746, 3658.36999512]
},
index=pd.date_range("2016-07-18", periods=14, freq="D"),
)
forecaster.predict(steps=5, last_window=last_window_new)
╭──────────────────────────────── UnknownLevelWarning ─────────────────────────────────╮ │ `levels` {'series_new_1', 'series_new_2'} were not included in training. Unknown │ │ levels are encoded as NaN, which may cause the prediction to fail if the estimator │ │ does not accept NaN values. │ │ │ │ Category : skforecast.exceptions.UnknownLevelWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/utils/utils.py:1143 │ │ Suppress : warnings.simplefilter('ignore', category=UnknownLevelWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
| level | pred | |
|---|---|---|
| 2016-08-01 | series_new_1 | 143.781101 |
| 2016-08-01 | series_new_2 | 143.781101 |
| 2016-08-02 | series_new_1 | 145.612148 |
| 2016-08-02 | series_new_2 | 145.612148 |
| 2016-08-03 | series_new_1 | 146.013700 |
| 2016-08-03 | series_new_2 | 146.013700 |
| 2016-08-04 | series_new_1 | 146.013700 |
| 2016-08-04 | series_new_2 | 146.013700 |
| 2016-08-05 | series_new_1 | 146.013700 |
| 2016-08-05 | series_new_2 | 146.013700 |
# Predecir nuevas series sin datos históricos disponibles
# ==============================================================================
# Crear un dataframe con la última ventana de la nueva serie con valores nan
last_window_new = pd.DataFrame(
{
"series_new_1": np.nan,
"series_new_2": np.nan
},
index=pd.date_range("2016-07-18", periods=14, freq="D"),
)
forecaster.predict(steps=5, last_window=last_window_new)
╭──────────────────────────────── UnknownLevelWarning ─────────────────────────────────╮ │ `levels` {'series_new_1', 'series_new_2'} were not included in training. Unknown │ │ levels are encoded as NaN, which may cause the prediction to fail if the estimator │ │ does not accept NaN values. │ │ │ │ Category : skforecast.exceptions.UnknownLevelWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/utils/utils.py:1143 │ │ Suppress : warnings.simplefilter('ignore', category=UnknownLevelWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
╭──────────────────────────────── MissingValuesWarning ────────────────────────────────╮ │ `last_window` has missing values. Most of machine learning models do not allow │ │ missing values. Prediction method may fail. │ │ │ │ Category : skforecast.exceptions.MissingValuesWarning │ │ Location : │ │ /home/ubuntu/anaconda3/envs/skforecast_22_py13/lib/python3.13/site-packages/skforeca │ │ st/utils/utils.py:1223 │ │ Suppress : warnings.simplefilter('ignore', category=MissingValuesWarning) │ ╰──────────────────────────────────────────────────────────────────────────────────────╯
| level | pred | |
|---|---|---|
| 2016-08-01 | series_new_1 | 62.453964 |
| 2016-08-01 | series_new_2 | 62.453964 |
| 2016-08-02 | series_new_1 | 61.960619 |
| 2016-08-02 | series_new_2 | 61.960619 |
| 2016-08-03 | series_new_1 | 61.594364 |
| 2016-08-03 | series_new_2 | 61.594364 |
| 2016-08-04 | series_new_1 | 61.594364 |
| 2016-08-04 | series_new_2 | 61.594364 |
| 2016-08-05 | series_new_1 | 61.039157 |
| 2016-08-05 | series_new_2 | 61.039157 |
Conclusiones¶
Este caso de uso muestra como un modelo multiserie puede presentar ventajas sobre varios modelos individuales cuando se predicen series temporales con una dinámica similar. Más allá de las posibles mejoras en la predicción, también es importante tener en cuenta la ventaja de tener un solo modelo que mantener.
Información de sesión¶
import session_info
session_info.show(html=False)
----- matplotlib 3.10.8 numpy 2.1.3 optuna 4.8.0 pandas 2.3.3 session_info v1.0.1 skforecast 0.22.0 sklearn 1.7.2 tqdm 4.67.3 ----- IPython 9.11.0 jupyter_client 8.8.0 jupyter_core 5.9.1 ----- Python 3.13.12 | packaged by Anaconda, Inc. | (main, Feb 24 2026, 16:13:31) [GCC 14.3.0] Linux-5.15.0-1084-aws-x86_64-with-glibc2.31 ----- Session information updated at 2026-04-23 12:52
Instrucciones para citar¶
¿Cómo citar este documento?
Si utilizas este documento o alguna parte de él, te agradecemos que lo cites. ¡Muchas gracias!
Modelos de forecasting globales: modelado de múltiples series temporales con machine learning por Joaquín Amat Rodrigo and Javier Escobar Ortiz, disponible con licencia Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0 DEED) en https://www.cienciadedatos.net/documentos/py44-multi-series-forecasting-skforecast-español.html
¿Cómo citar skforecast?
Si utilizas skforecast, te agradeceríamos mucho que lo cites. ¡Muchas gracias!
Zenodo:
Amat Rodrigo, Joaquin, & Escobar Ortiz, Javier. (2024). skforecast (v0.22.0). Zenodo. https://doi.org/10.5281/zenodo.8382788
APA:
Amat Rodrigo, J., & Escobar Ortiz, J. (2024). skforecast (Version 0.22.0) [Computer software]. https://doi.org/10.5281/zenodo.8382788
BibTeX:
@software{skforecast, author = {Amat Rodrigo, Joaquin and Escobar Ortiz, Javier}, title = {skforecast}, version = {0.22.0}, month = {03}, year = {2026}, license = {BSD-3-Clause}, url = {https://skforecast.org/}, doi = {10.5281/zenodo.8382788} }
¿Te ha gustado el artículo? Tu ayuda es importante
Tu contribución me ayudará a seguir generando contenido divulgativo gratuito. ¡Muchísimas gracias! 😊




Este documento creado por Joaquín Amat Rodrigo y Javier Escobar Ortiz tiene licencia Attribution-NonCommercial-ShareAlike 4.0 International.
Se permite:
-
Compartir: copiar y redistribuir el material en cualquier medio o formato.
-
Adaptar: remezclar, transformar y crear a partir del material.
Bajo los siguientes términos:
-
Atribución: Debes otorgar el crédito adecuado, proporcionar un enlace a la licencia e indicar si se realizaron cambios. Puedes hacerlo de cualquier manera razonable, pero no de una forma que sugiera que el licenciante te respalda o respalda tu uso.
-
No-Comercial: No puedes utilizar el material para fines comerciales.
-
Compartir-Igual: Si remezclas, transformas o creas a partir del material, debes distribuir tus contribuciones bajo la misma licencia que el original.